CUDA
一、GPU硬件资源
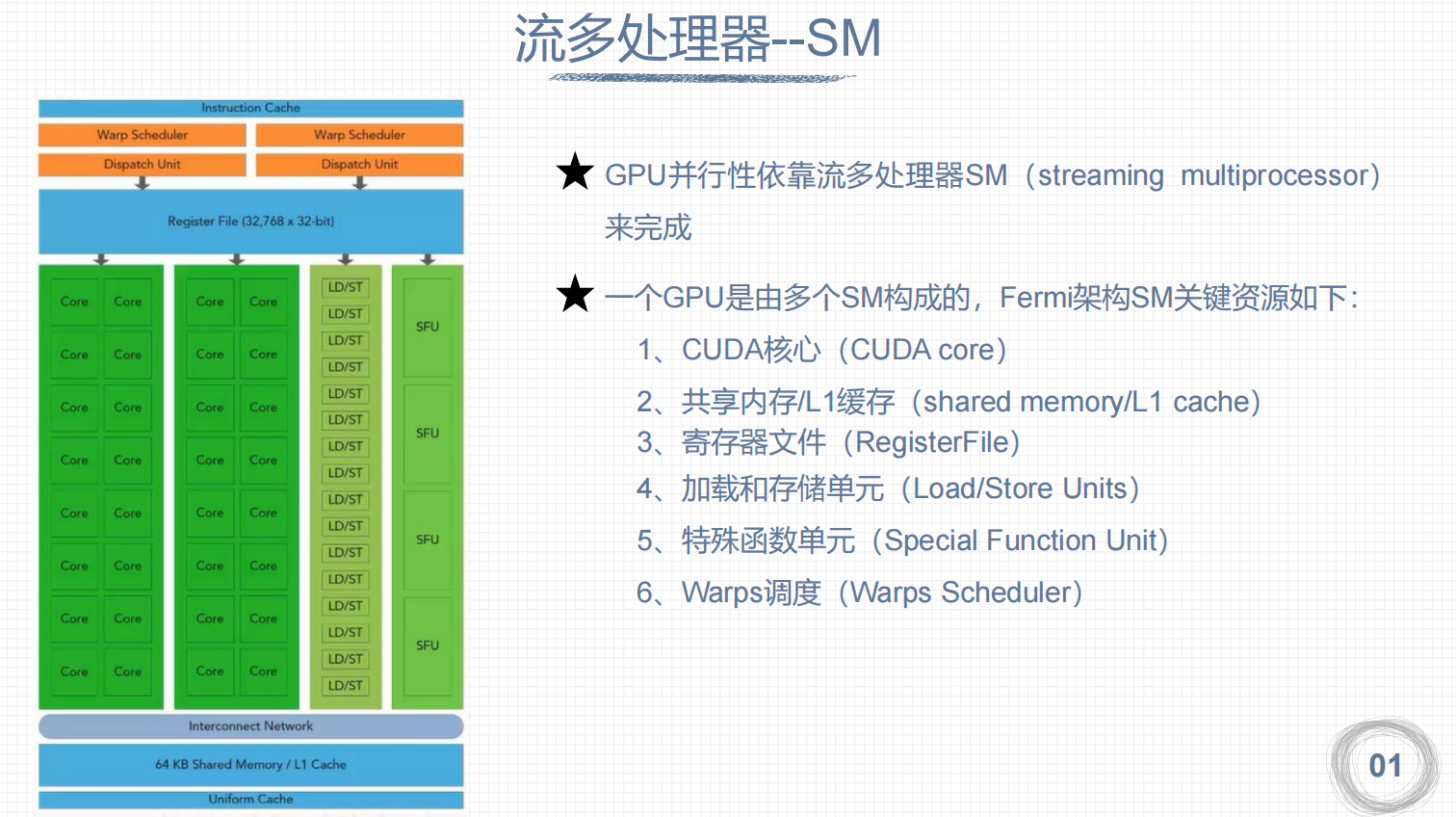
1. 流多处理器--SM
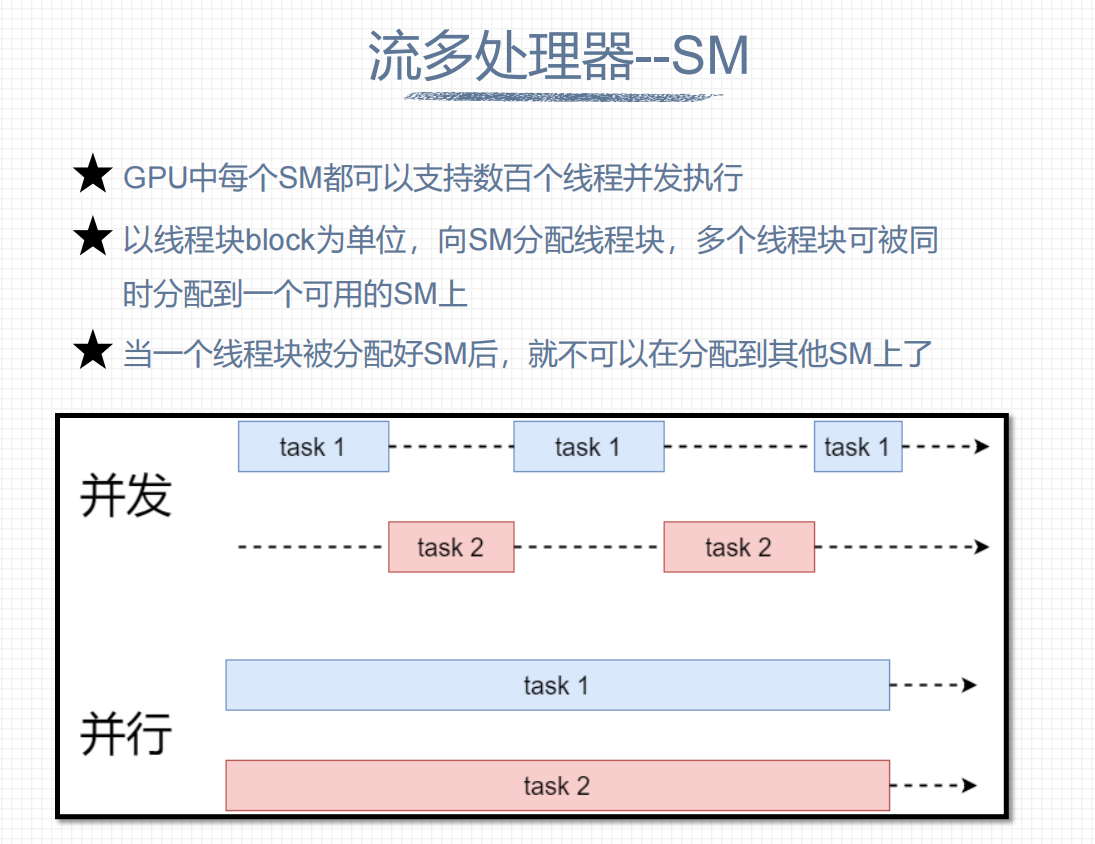 串行和并发的区别:
串行和并发的区别:
- 硬件执行单元利用
串行执行:
流水线停顿(Pipeline Stall):数据依赖导致流水线气泡
资源闲置:ALU、FPU等执行单元利用率低(通常<30%)
冯·诺依曼瓶颈:单一指令流,顺序访问内存
并发执行:
多发射(Multiple Issue):单周期发射多条指令
执行单元并行:多个ALU/FPU同时工作
乱序执行(OoOE):动态调度隐藏延迟
- 内存层次结构影响
串行内存访问:
CPU核心 → L1 Cache → L2 Cache → L3 Cache → 内存 → 磁盘 ↓ ↓ ↓ ↓ ↓ 命中延迟 命中延迟 命中延迟 100ns 10ms (1ns) (4ns) (10ns) │ │ └── 内存墙问题 ──┘
并行访问:
核心1 → L1 → L2 → L3 → 内存控制器 → DRAM Bank 1 核心2 → L1 → L2 → L3 → 内存控制器 → DRAM Bank 2 核心3 → L1 → L2 → L3 → 内存控制器 → DRAM Bank 3 核心4 → L1 → L2 → L3 → 内存控制器 → DRAM Bank 4 ↓ ↓ ↓ ↓ ↓ 并行访存 独立 共享但 交错访问 Bank并行 缓存 分区
关键差异:
行缓冲冲突:串行访问同一DRAM Bank导致频繁预充电
总线竞争:单一线程无法饱和内存带宽
预取效率:并发可隐藏预取延迟
- 现代CPU架构的并发支持
多级并行体系
指令级并行 (ILP) ├── 流水线 (Pipeline):5-20级深 ├── 超标量 (Superscalar):4-8路发射 ├── 乱序执行 (OoOE):192条指令重排序窗口 └── 推测执行 (Speculation):分支预测
线程级并行 (TLP) ├── 同步多线程 (SMT/Hyper-Threading):2-8线程/核心 ├── 多核心 (Multi-Core):4-128个物理核心 └── 众核心 (Many-Core):数千个简化核心
数据级并行 (DLP) ├── SIMD (SSE/AVX):256-512位向量 ├── GPU并行:数千个流处理器 └── 张量核心:专用矩阵运算
3.2 资源冲突对比
| 资源类型 | 串行执行问题 | 并发执行优势 | 瓶颈风险 |
|---|---|---|---|
| 执行端口 | 端口利用率低 | 多端口同时使用 | 端口竞争 |
| 重排序缓冲区 | 窗口空闲 | 多线程填充窗口 | ROB容量 |
| 缓存 | 局部性有限 | 多工作集预热缓存 | 缓存污染 |
| 内存带宽 | 无法饱和 | 聚合带宽利用 | 控制器竞争 |
| TLB | 页表覆盖小 | 多线程共享TLB | TLB抖动 |
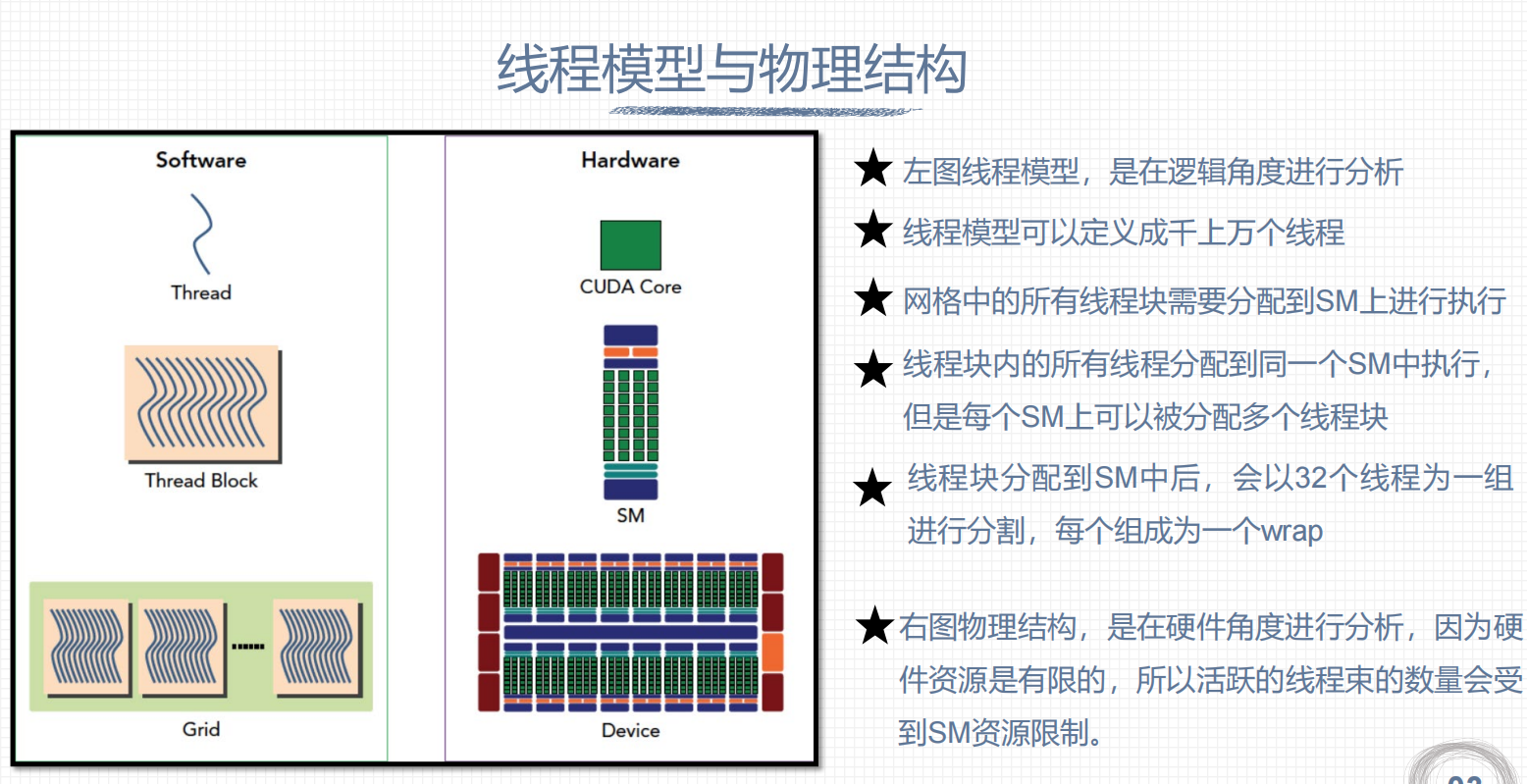
2. 线程模型与物理结构
3. 线程数束
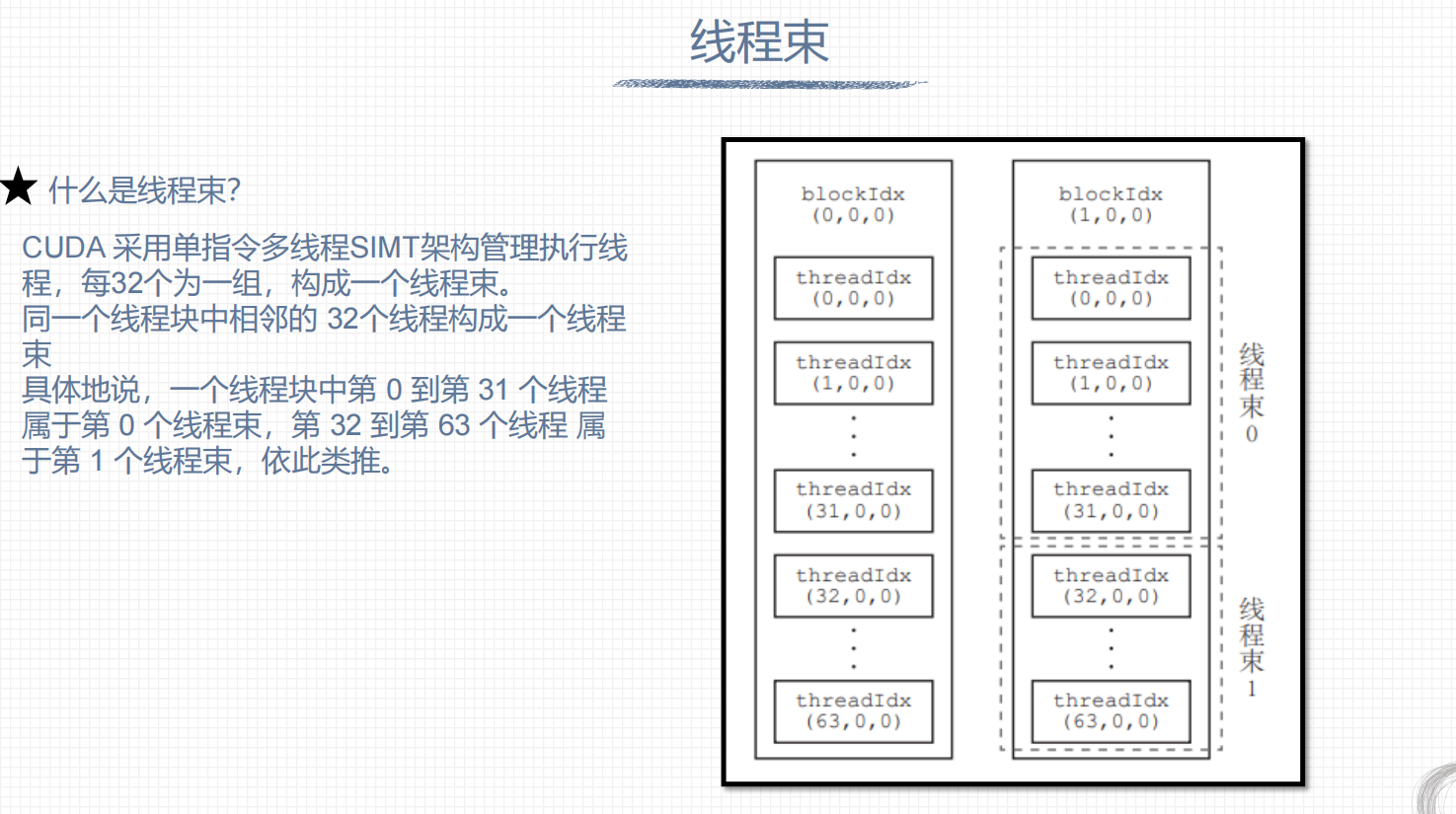
 为了最大化GPU效率,线程块内的线程个数是32的整数倍
为了最大化GPU效率,线程块内的线程个数是32的整数倍
二、CUDA内存模型概述
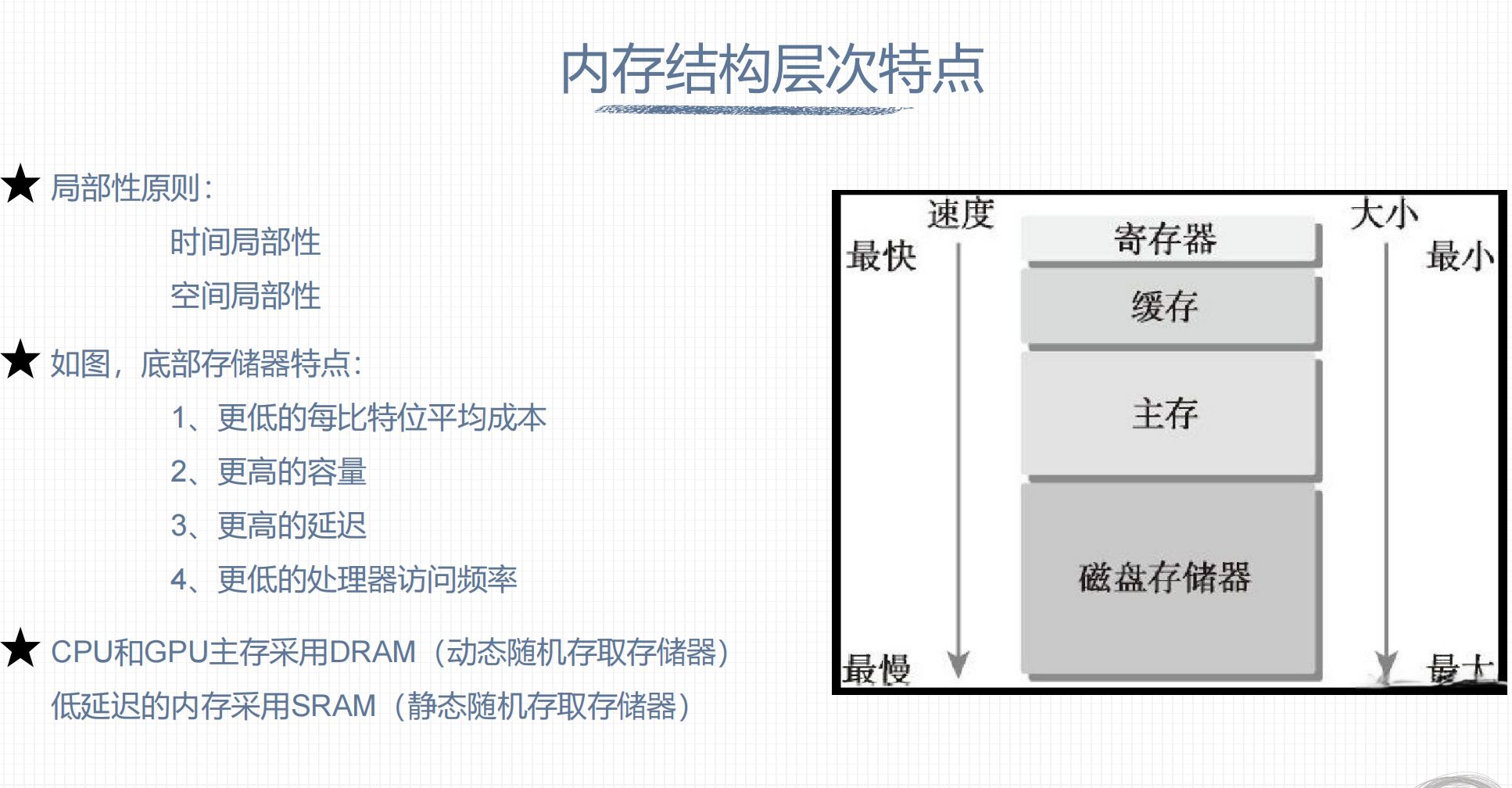
1. 内存结构层次特点
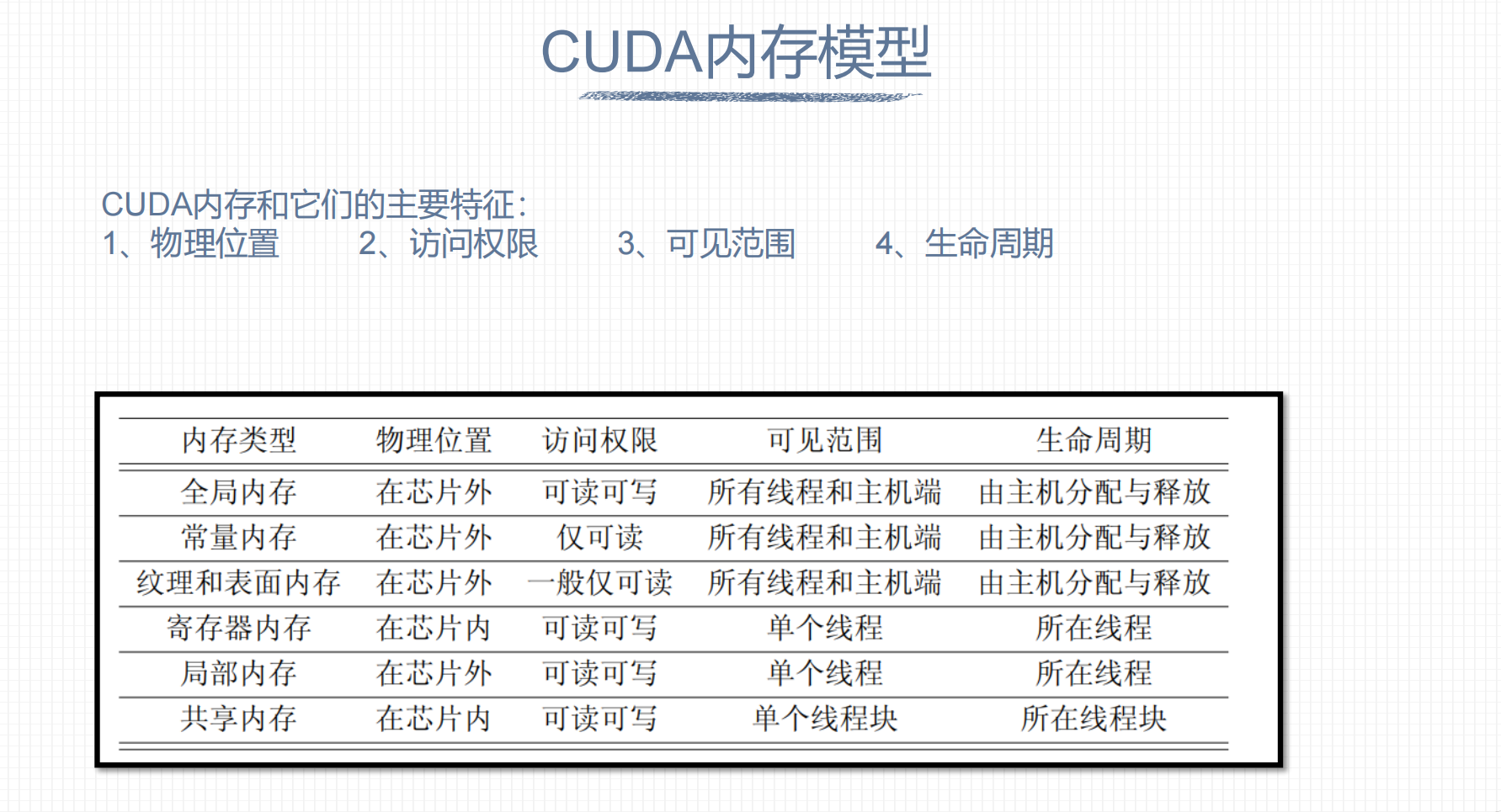
2. CUDA内存模型
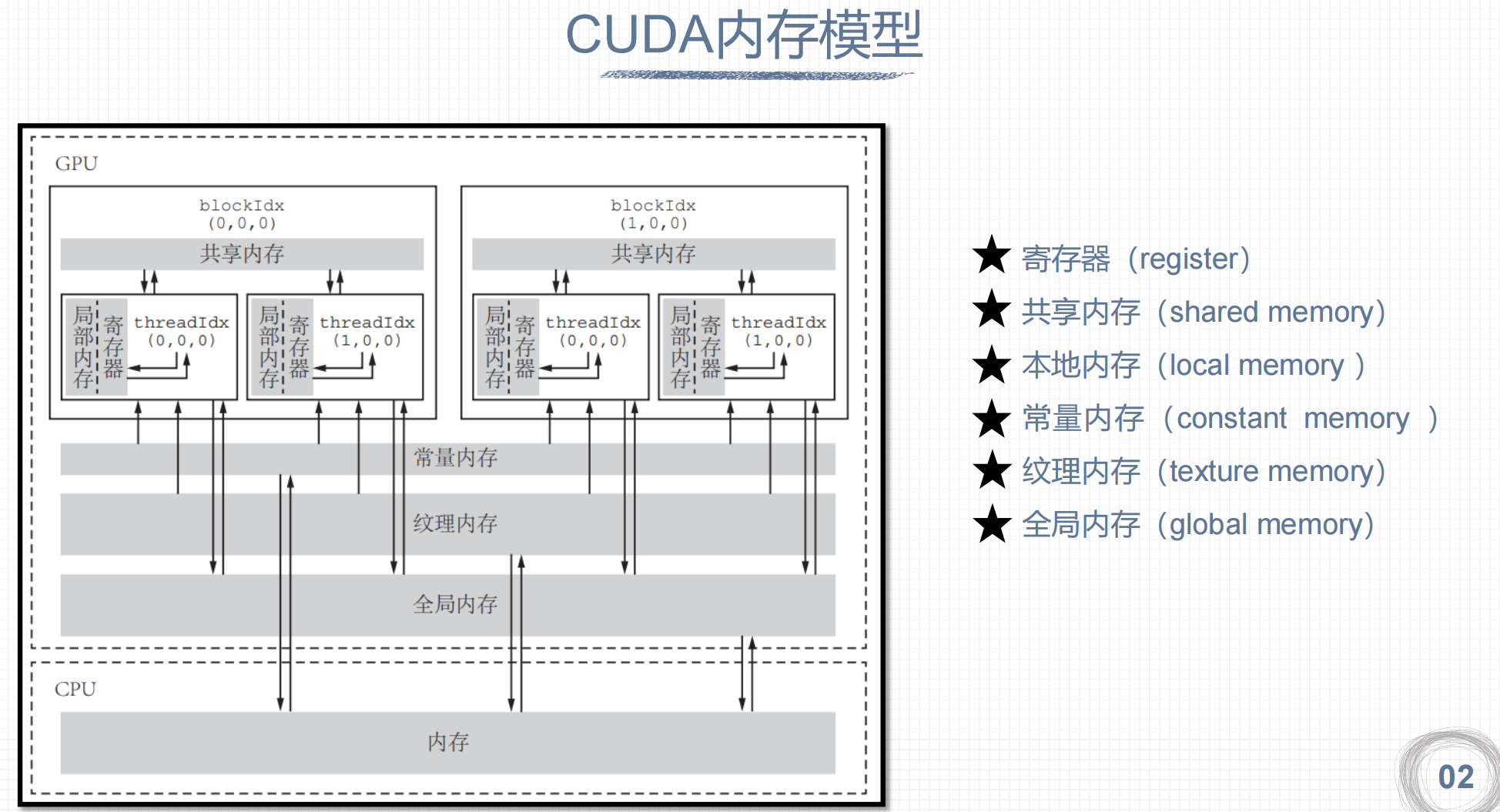 共享内存是片上内存
共享内存是片上内存
 # 三、寄存器和本地内存
# 三、寄存器和本地内存
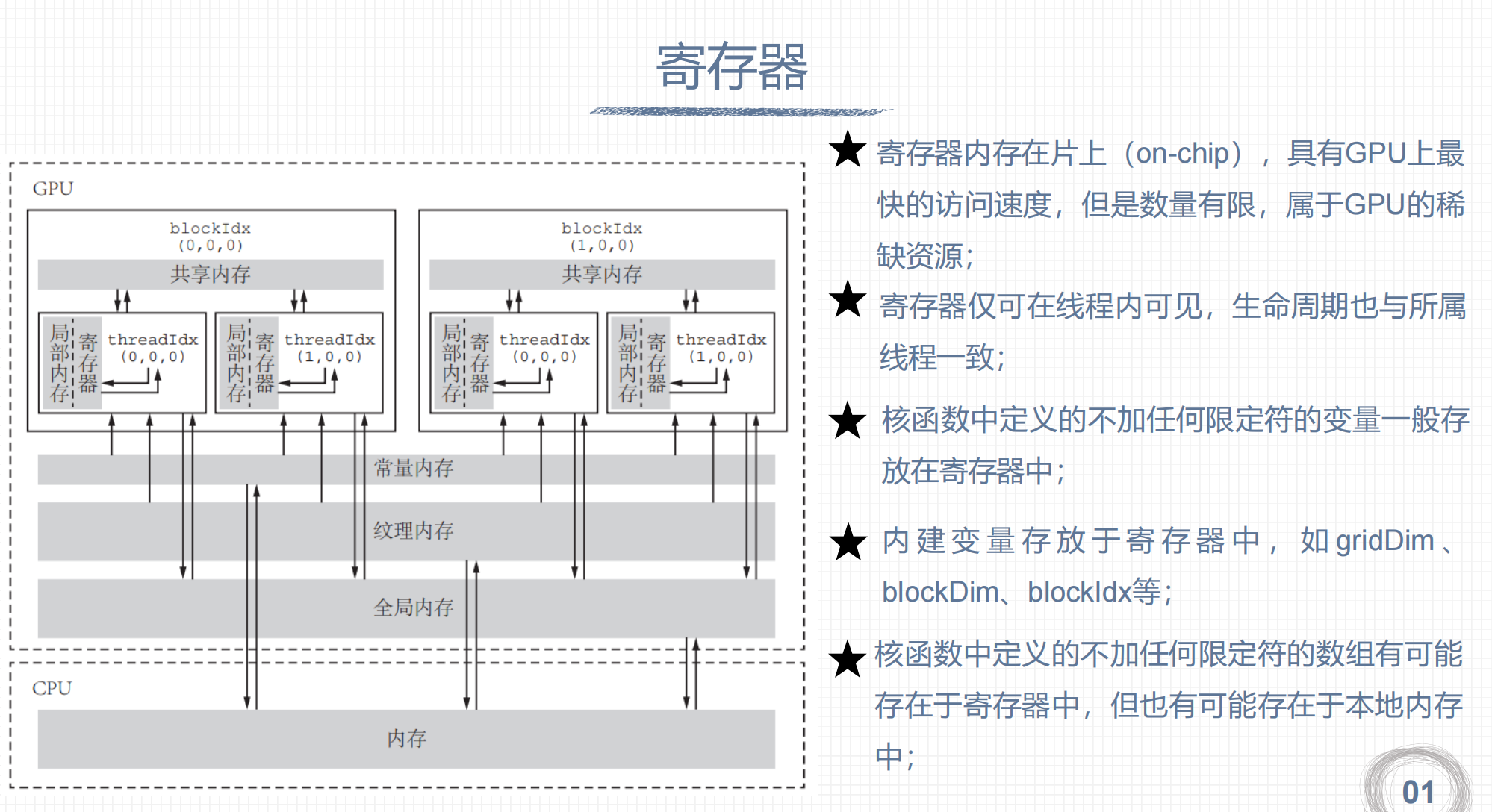
1. 寄存器

2. 本地内存
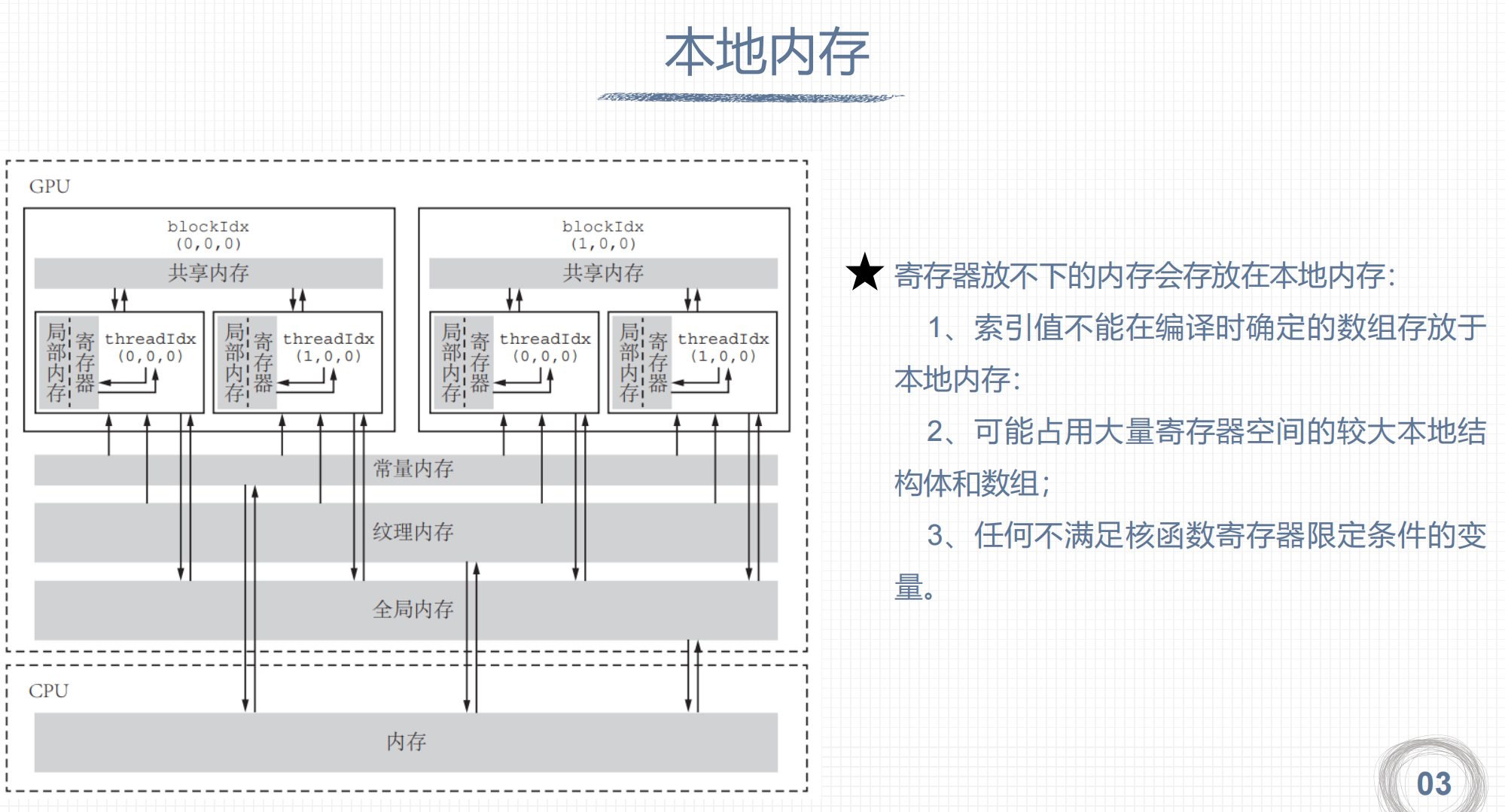

3. 寄存器溢出

1 | |
 全局内存使用为0,代表静态全局内存使用情况
全局内存使用为0,代表静态全局内存使用情况
四、全局内存
1. 全局内存
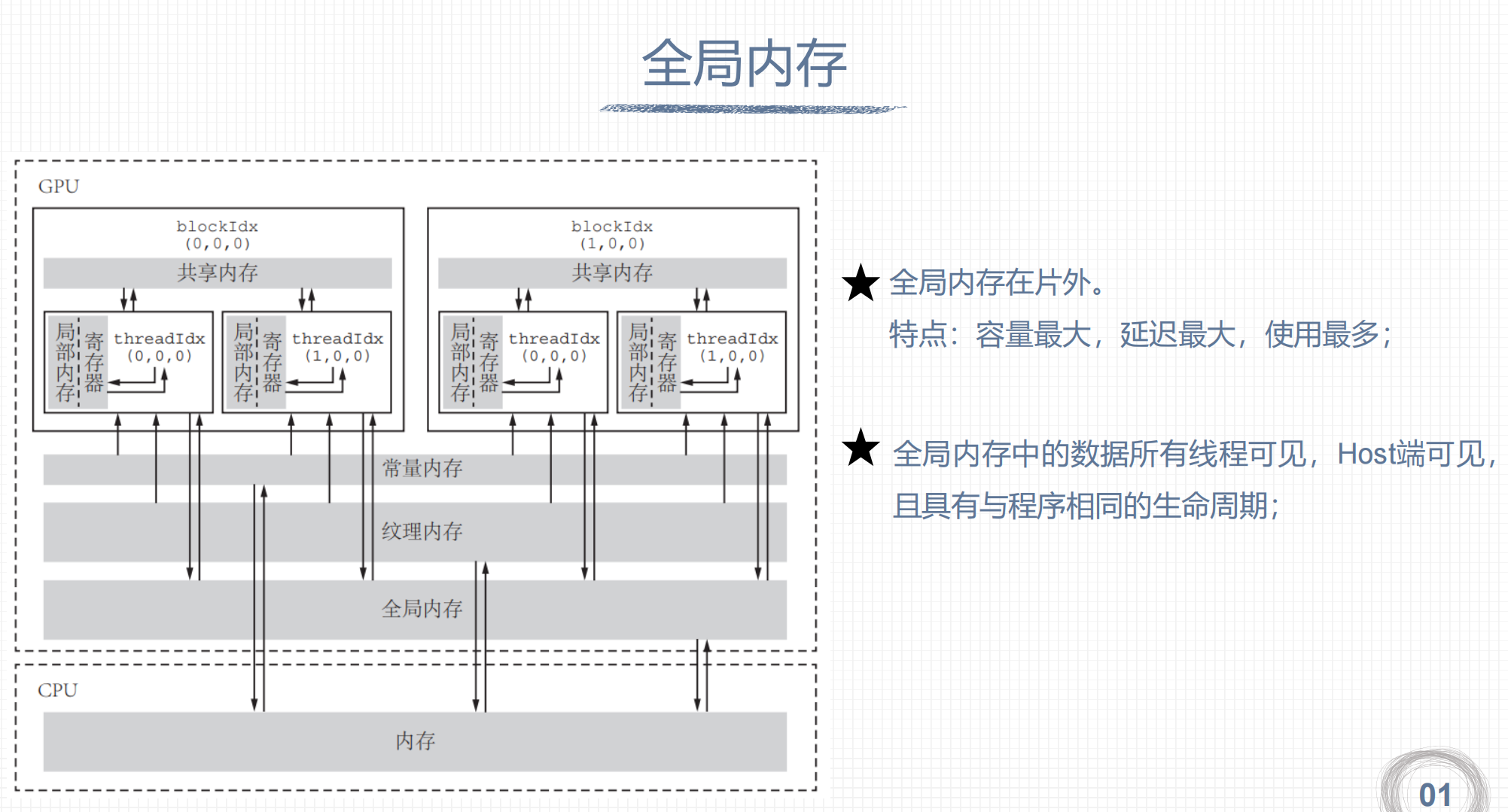
2. 全局内存初始化
 静态全局变量必须在主机和设备函数外定义
静态全局变量必须在主机和设备函数外定义
五、共享内存
1. 共享内存作用
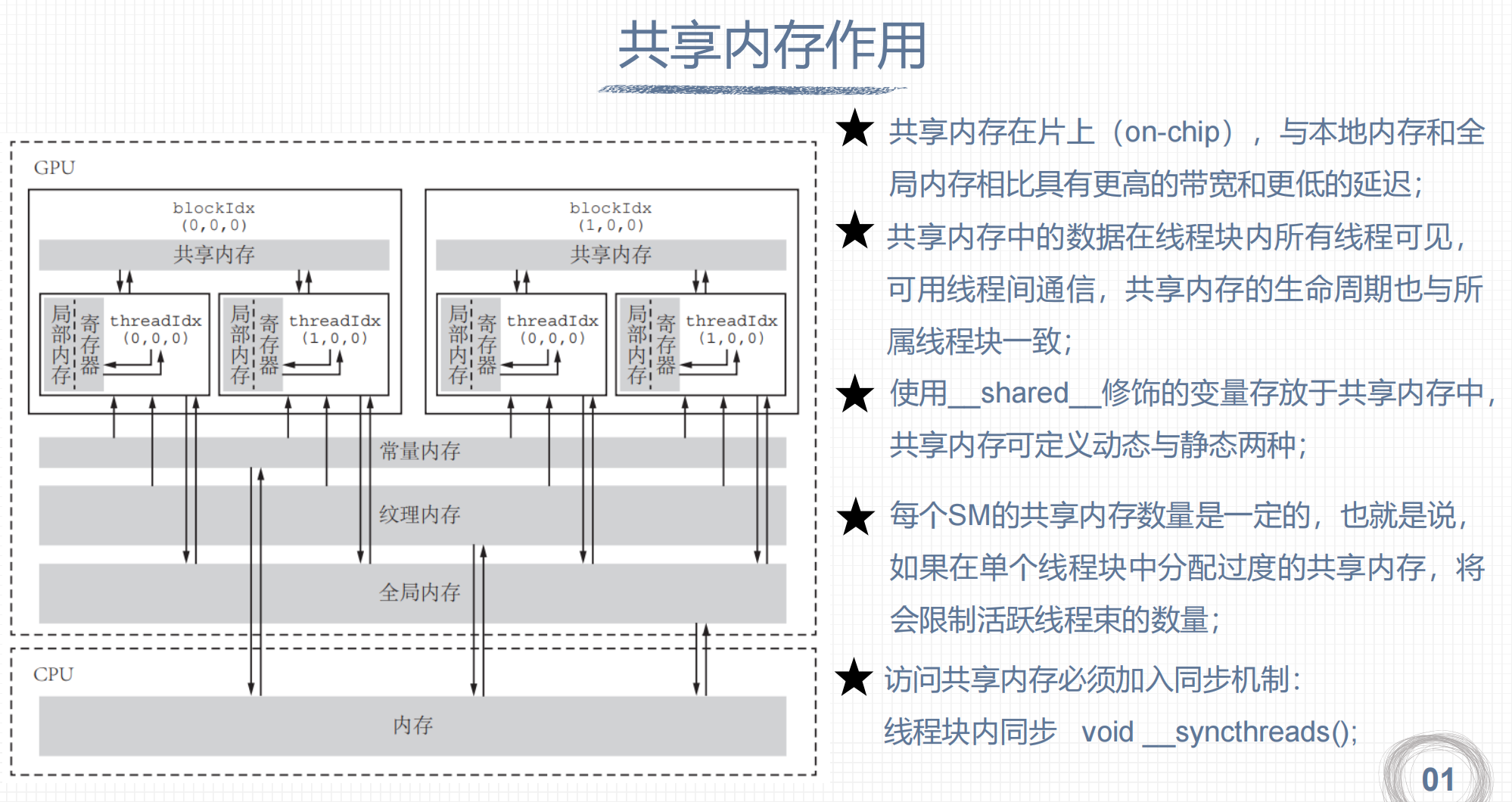
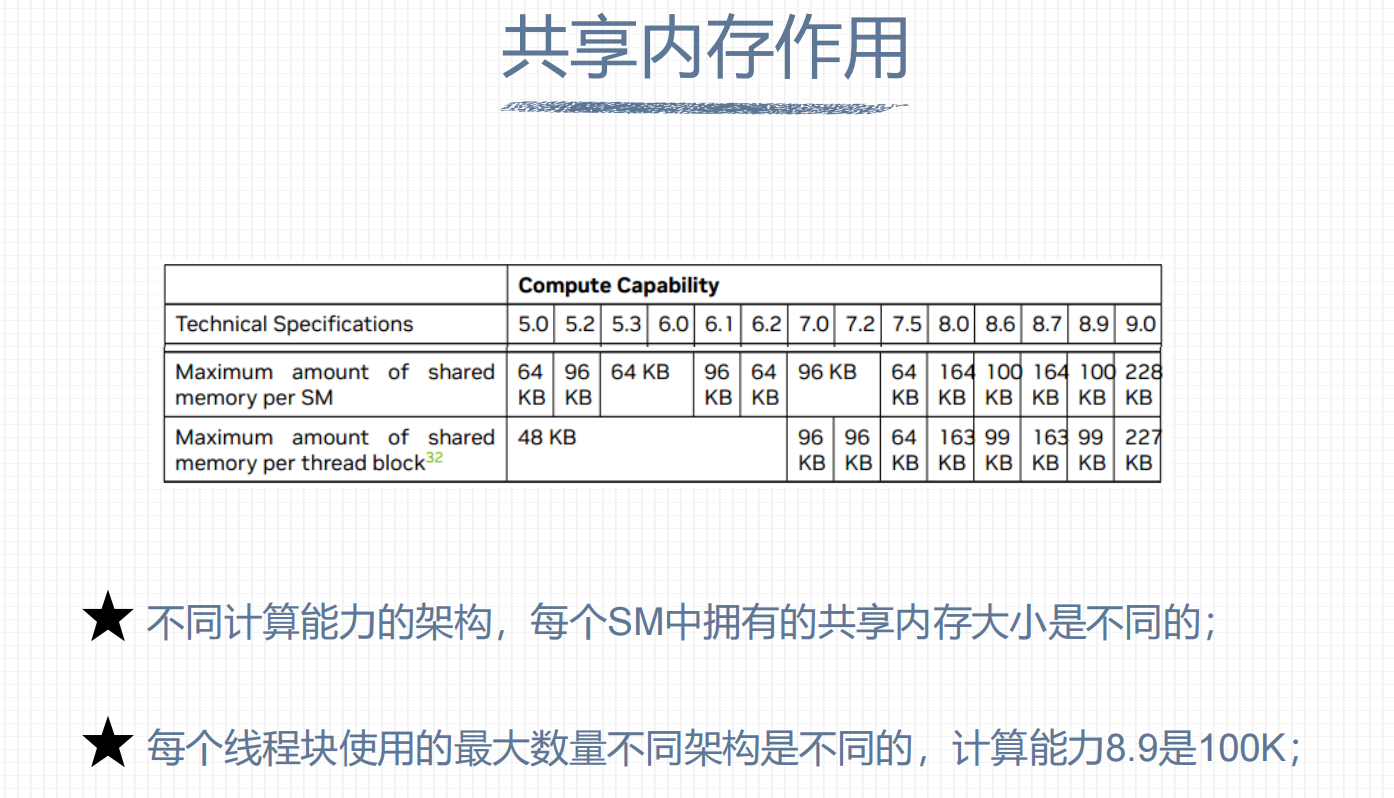

2. 静态共享内存
 cuda支持一维、二维和三维静态共享内存 ## 3. 动态共享内存
cuda支持一维、二维和三维静态共享内存 ## 3. 动态共享内存 
六、常量内存
1. 常量内存的作用
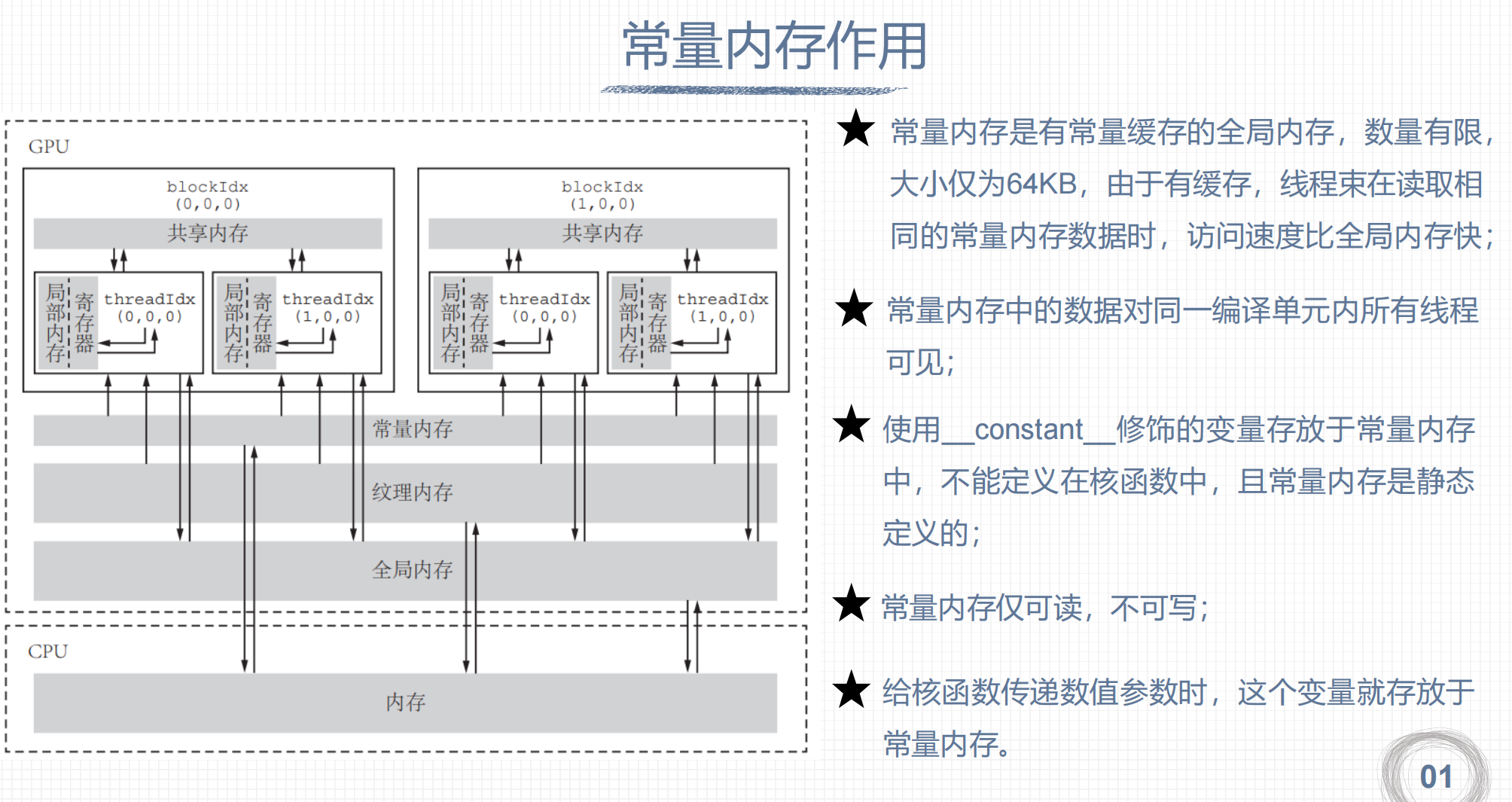
2. 常量内存的使用
 # 七、GPU缓存
# 七、GPU缓存
1. GPU缓存种类

2. GPU缓存作用
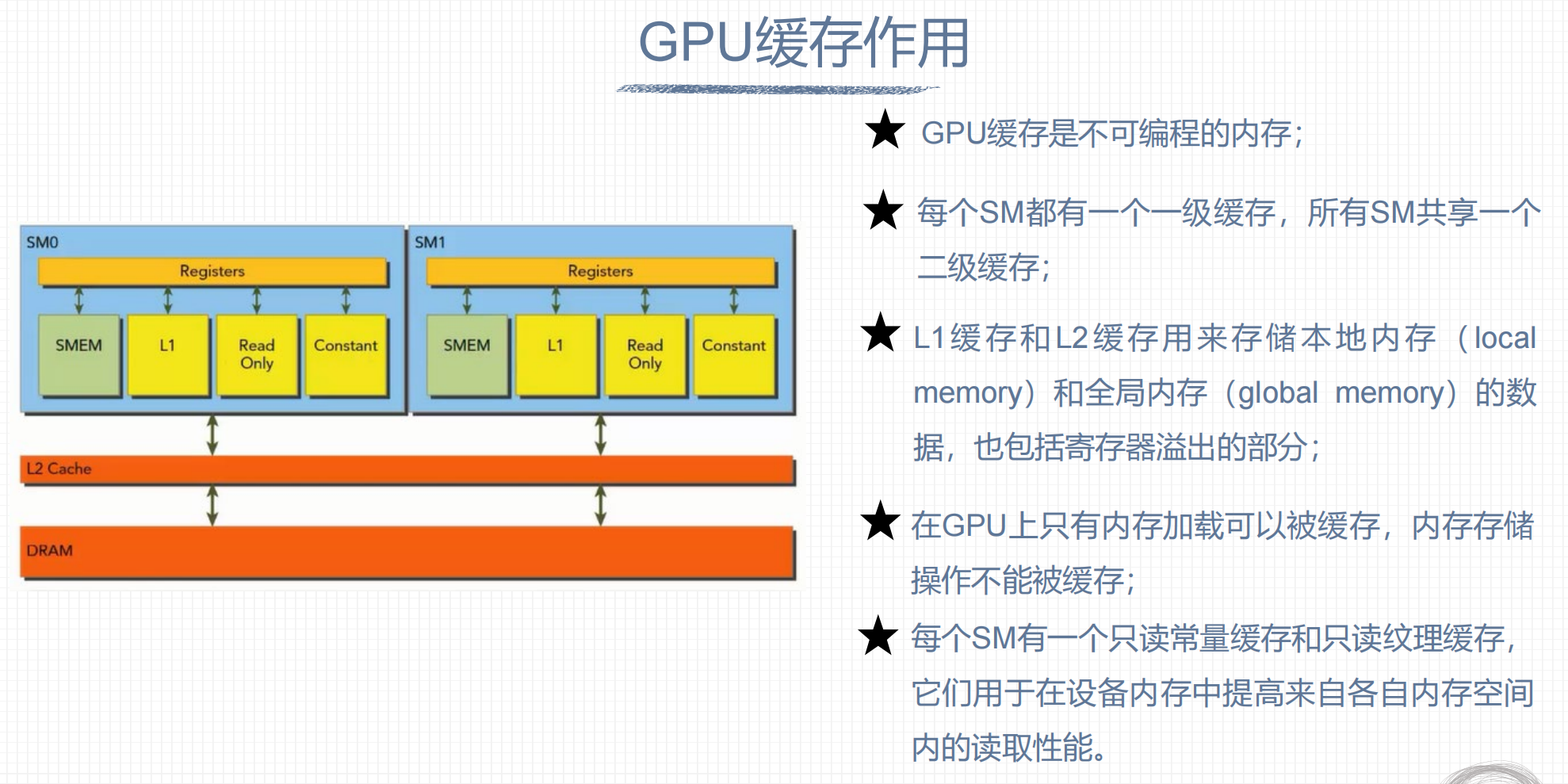 ## 3. L1缓存查询与设置
## 3. L1缓存查询与设置  ## 4. L1缓存共享内存
## 4. L1缓存共享内存 
