CUDA
一、CUDA矩阵加饭
1.1 CUDA程序基本框架

1.2 设置GPU设备

1.3 内存管理




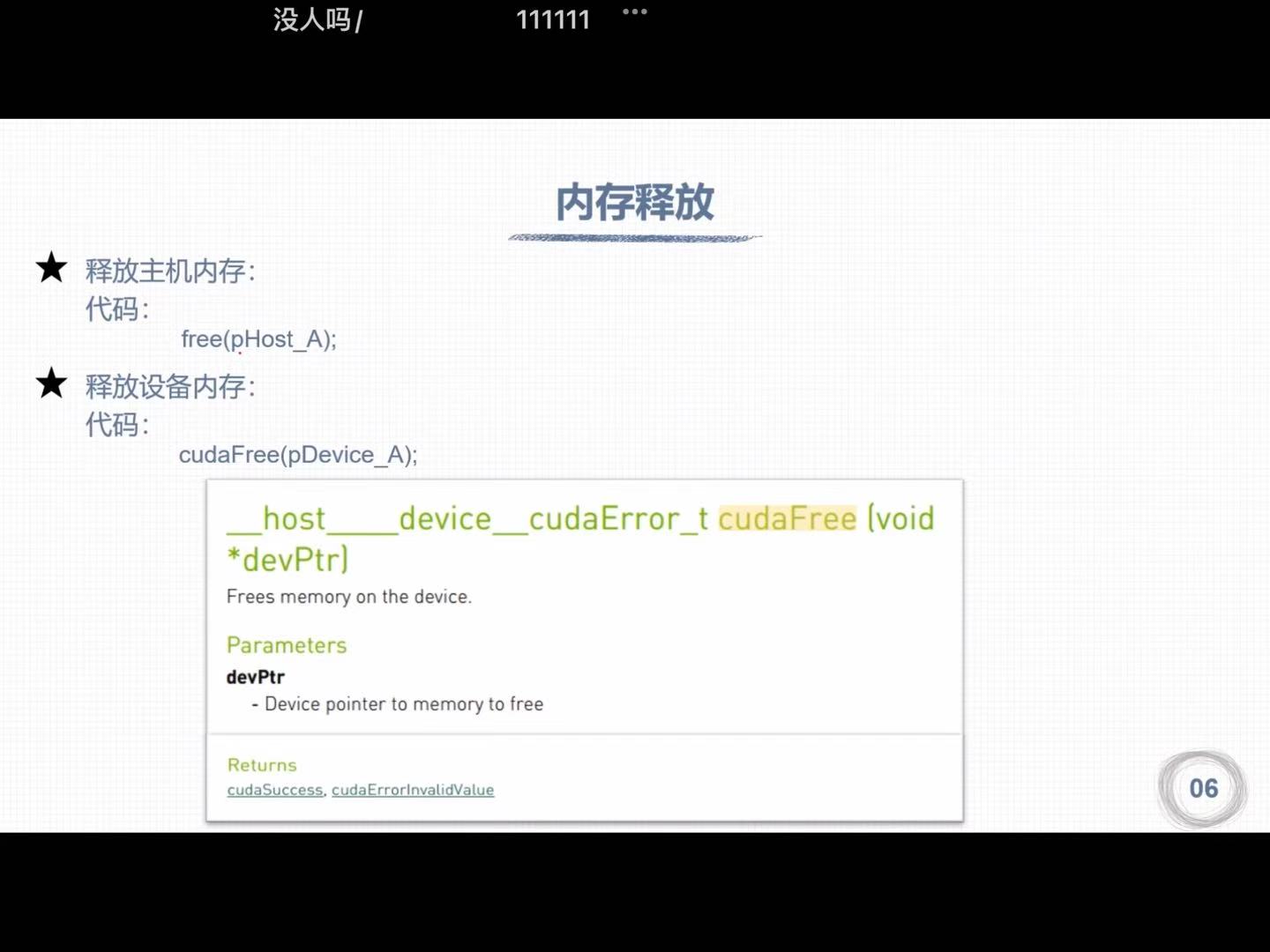

- 主机不能调用设备函数
二、CUDA错误检查
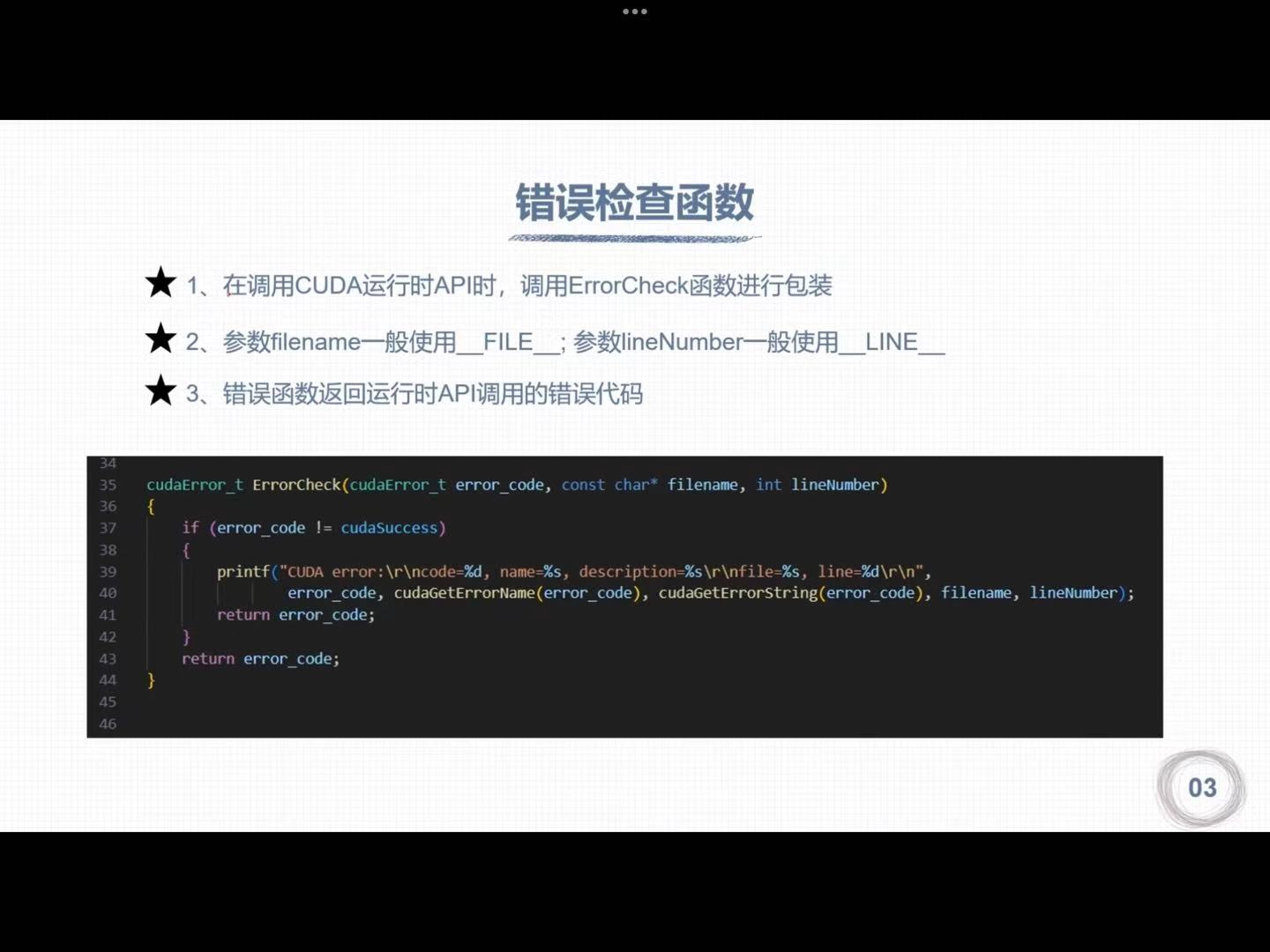
1. 运行时API错误代码

2. 错误检查函数

3. 检查核函数

三、CUDA计时
1. 时间计时

2. nvprof性能剖析
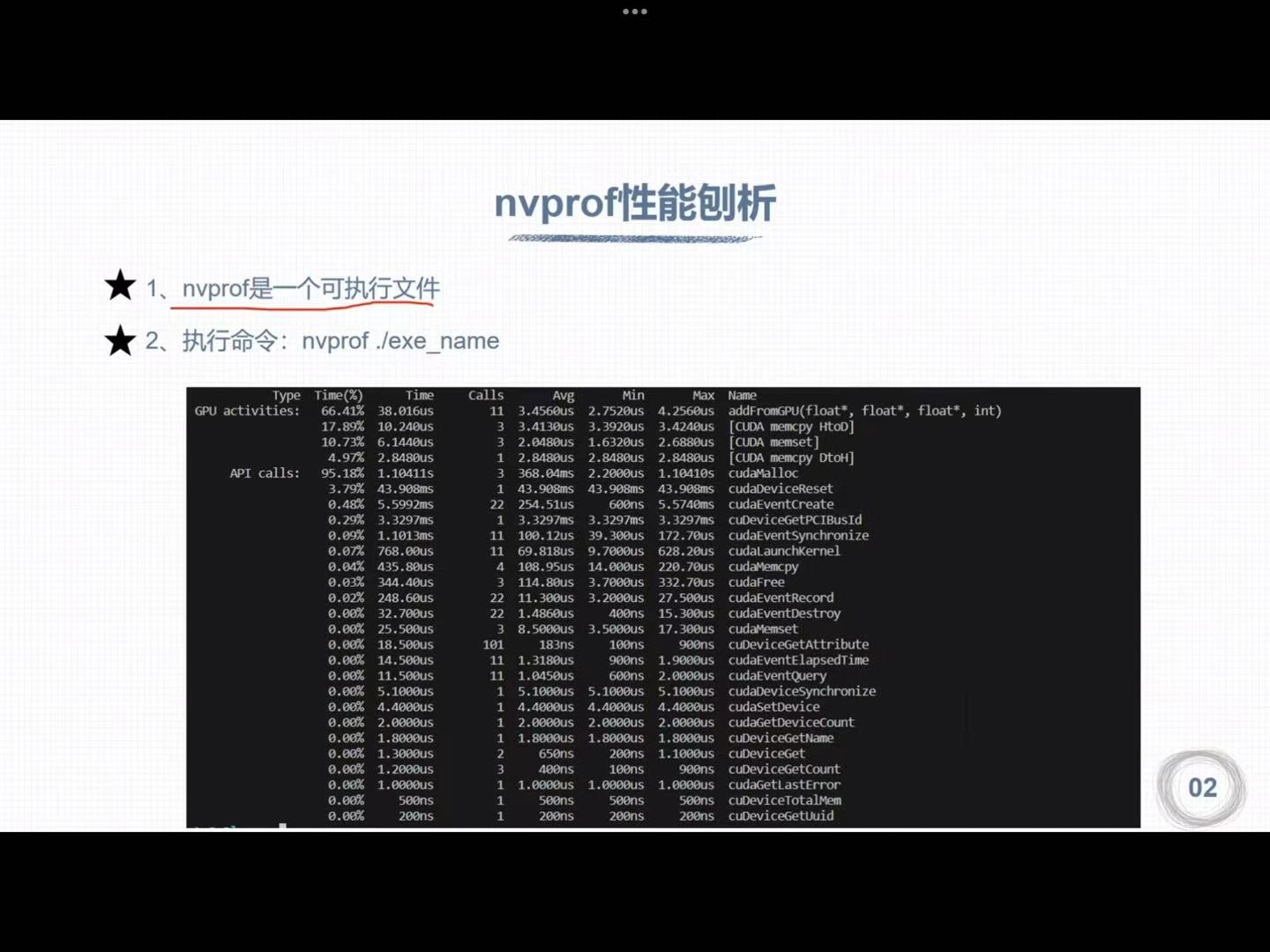
nsys nvprof ./***
四、运行时GPU信息查询
1. 运行时API查询GPU信息

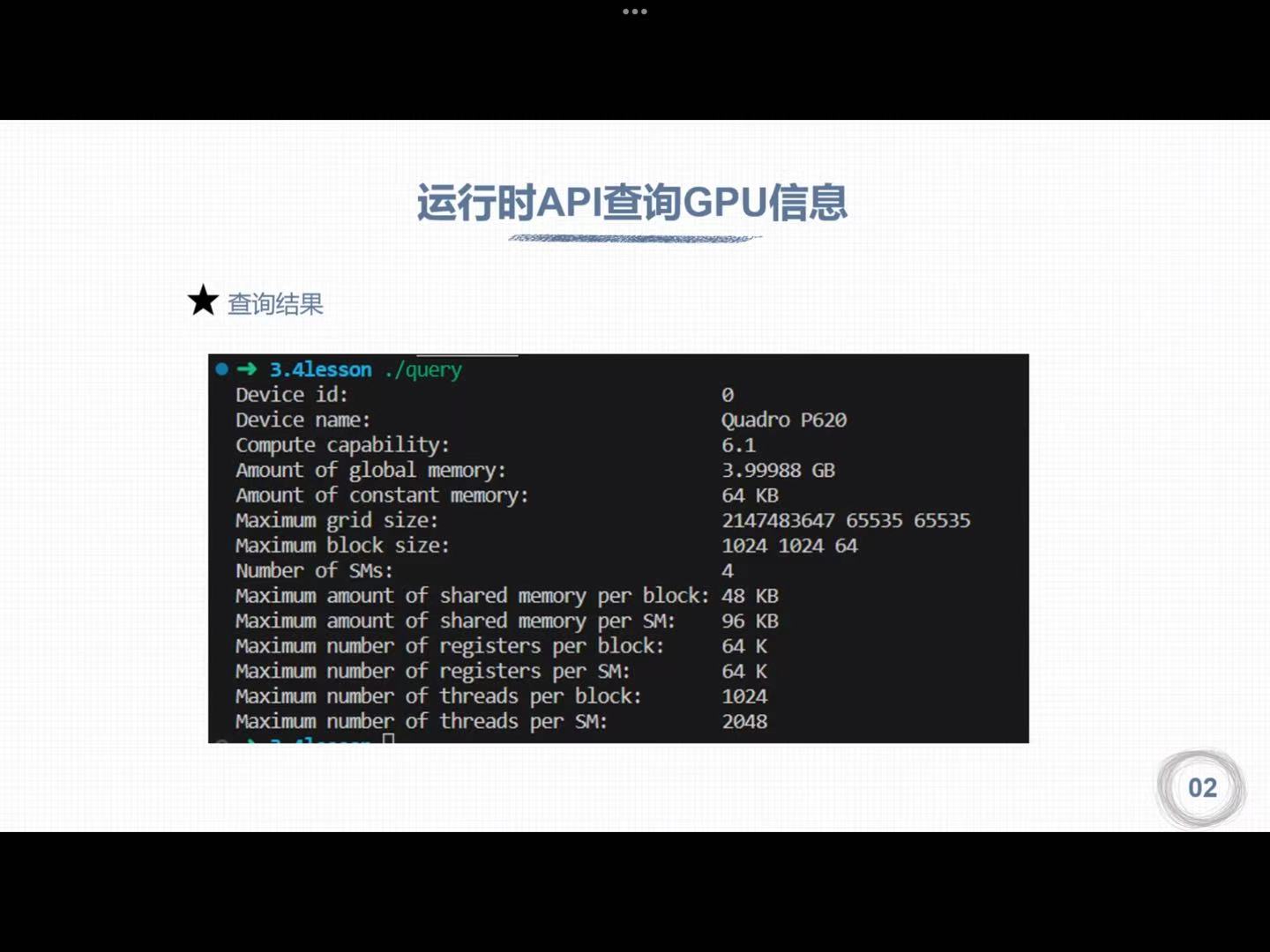
1 | |
2. 查询GPU计算核心数量
五、组织线程模型
1. 二维网格二维线程块
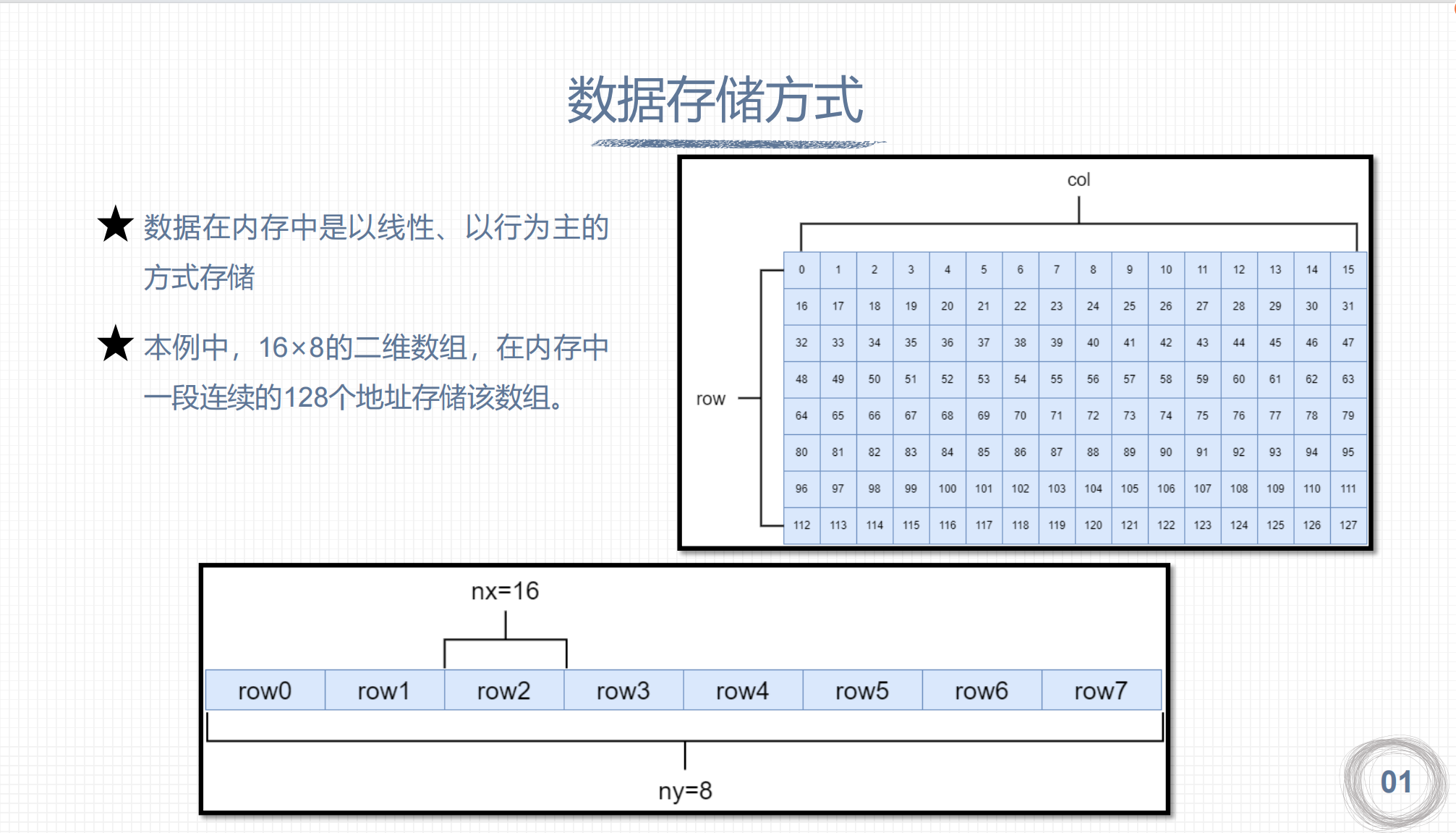
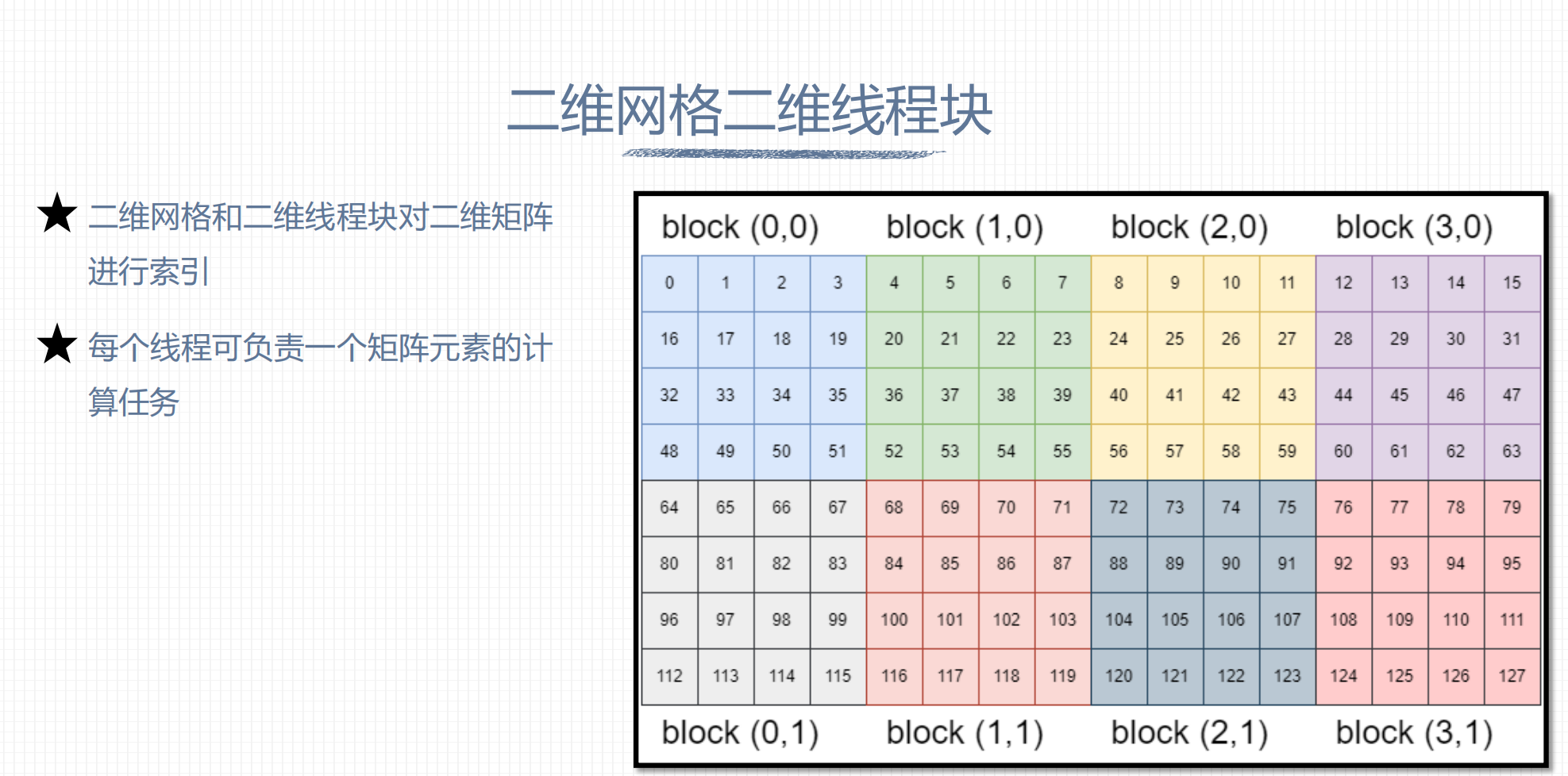
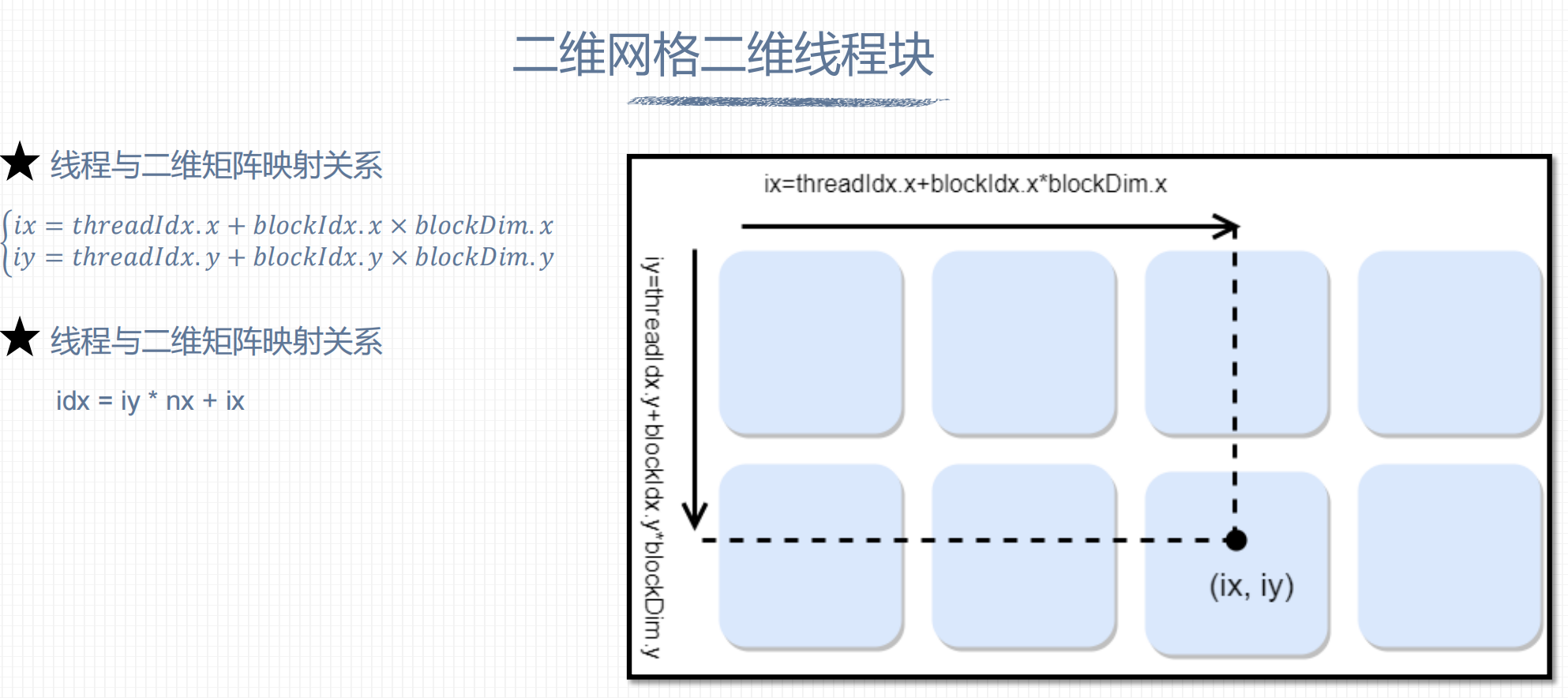
nx = blockDim.x * gridDim.x
nx: 矩阵宽
ny:矩阵长
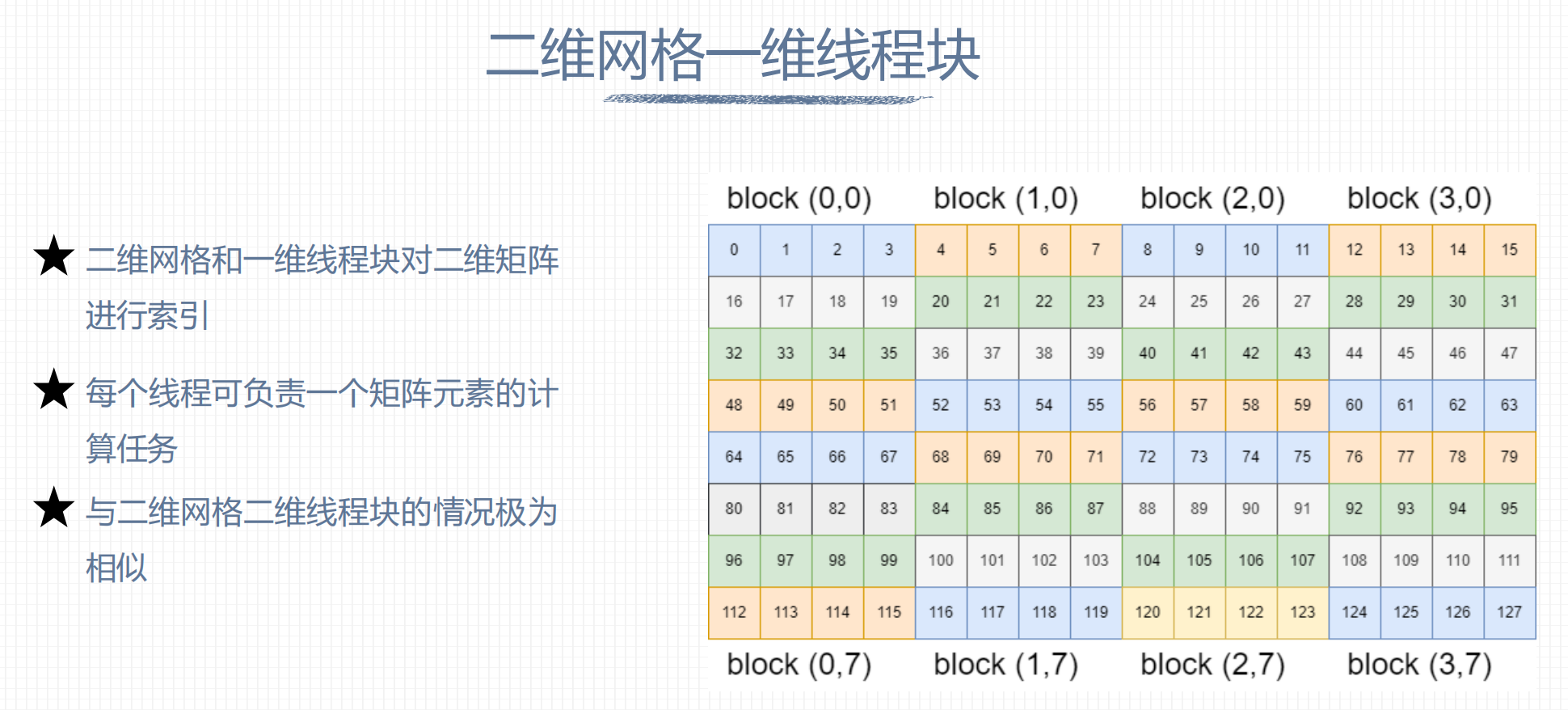
2. 二维网格一维线程块
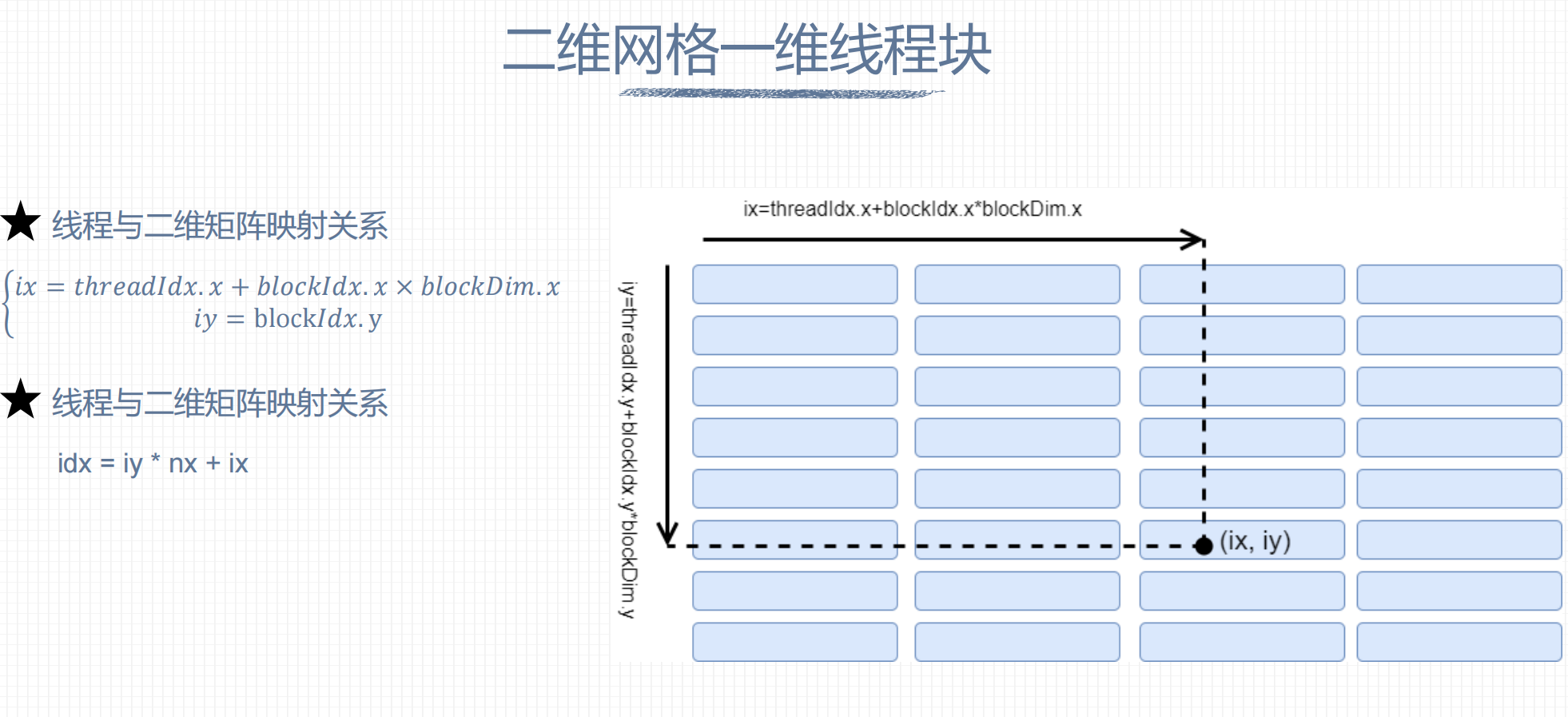
3. 一维网格一维线程块
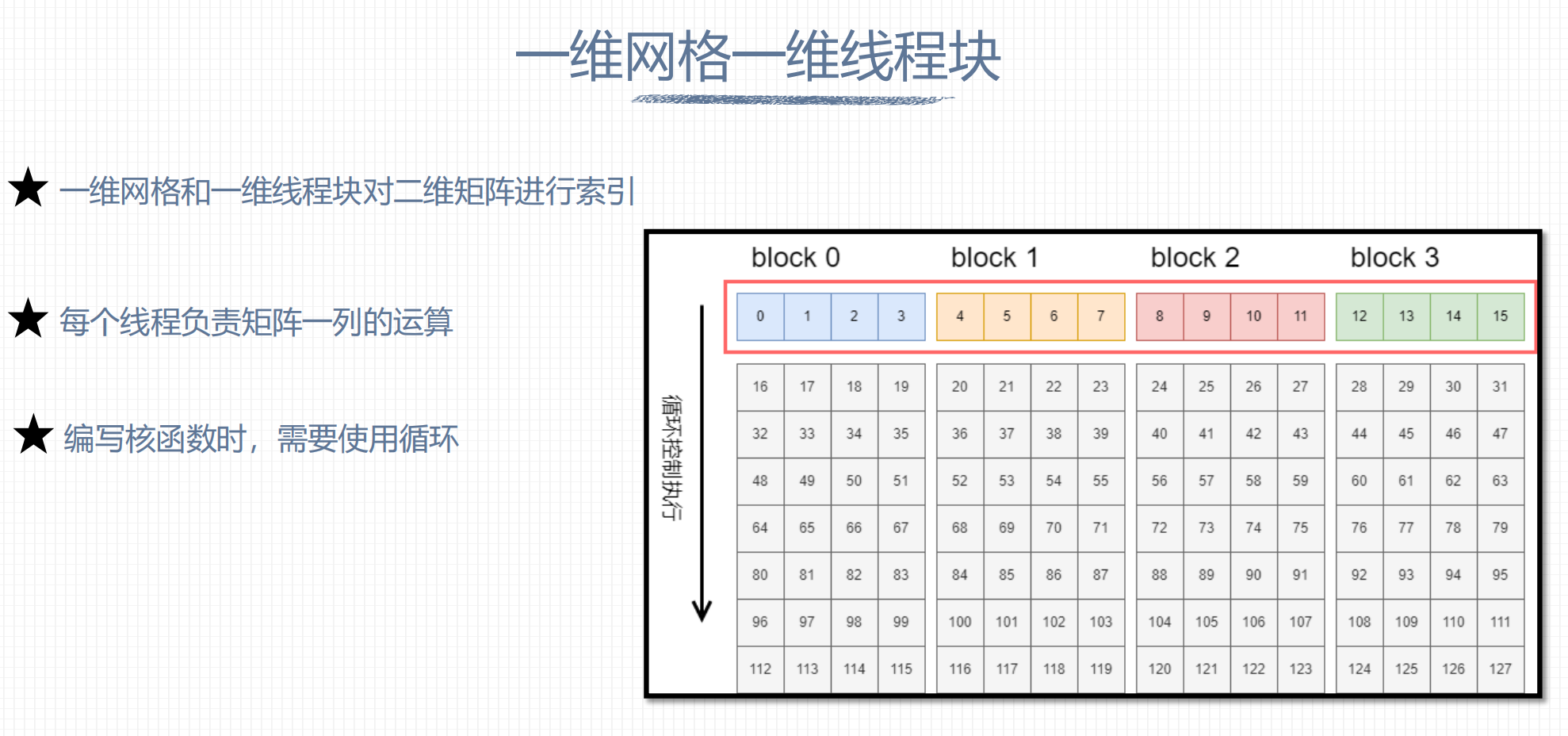
Matrix Plus
http://chenxindaaa.com/Infra/CUDA/infra/matrixAdd/