CUDA
一、核函数
核函数在GPU上并行执行
注意
- 限定词__global__修饰
- 返回值必须是void
形式
1
2
3
4__global__ void kernel_function(argument arg)
{
printf("hello world\n");
}1
2
3
4void __global__ kernel_function(argument arg)
{
printf("hello world\n");
}
核函数只能返回GPU内存
核函数不能使用变长参数
核函数不能使用静态变量
核函数不能使用函数指针
核函数具有异步性,需要用cudaDeviceSynchronize()同步
CUDA程序编写流程:
1 | |
注意: 核函数不支持C++的iostream
二、 CUDA线程模型
1. 线程模型结构
- 线程模型重要概念:
- grid 网格
- block 线程块,包含一组线程
- thread 线程 最小单位
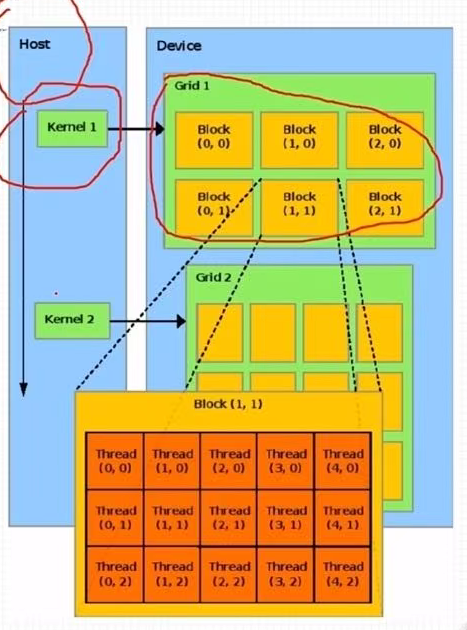
线程分块是逻辑上的划分,物理上线程不分块
配置线程:<<<grid_size, block_size>>>, 一个grid grid_size个block,一个block block_size个thread
最大允许线程块大小:1024
最大允许网格大小:\(2^{31} - 1\) (针对唯一网格)
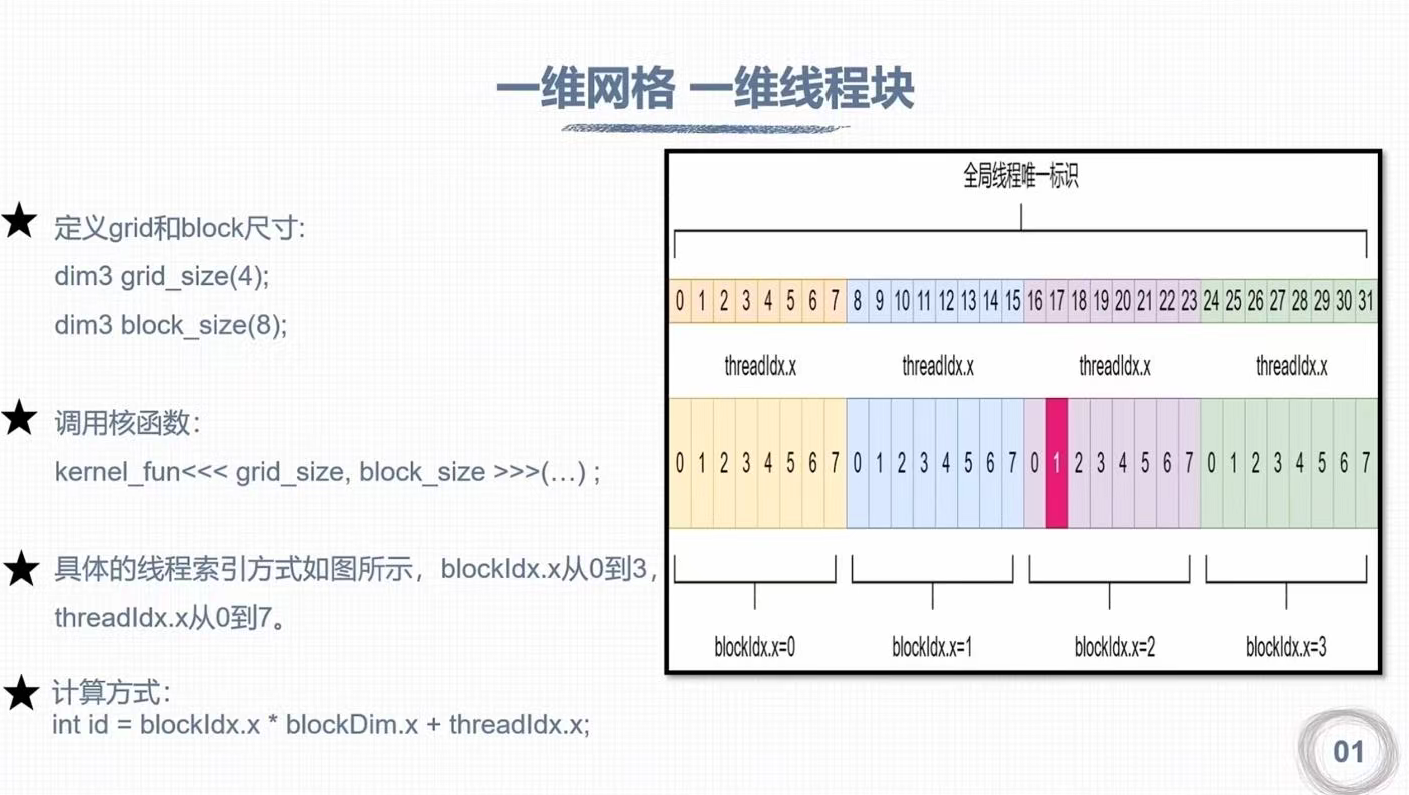
2. 一维线程模型
每个线程在核函数中都有一个唯一的身份标识;
每个线程的唯一标识由这两个<<<grid_size, block_size>>>确定;grid_size, block_size保存在内建变量(build-in variable),目前考虑的是一维的情况:
gridDim.x:该变量的数值等于执行配置中变量grid_size的值;
blockDim.x:该变量的数值等于执行配置中变量block_size的值。
- 线程索引保存成内建变量
blockIdx.x:改变量指定一个线程在一个网格中的线程块索引值,范围为0~gridDim.x-1;
threadIdx.x:该变量指定一个线程在一个线程块中的线程索引值,范围为0~blockDim.x - 1。
example:
kernel_func<<<2, 4>>>();
gridDimx.x = 2
blockDimx.x = 4
0 <= blockIdx.x <= 1
0 <= threadIdx.x <= 3
线程唯一标识:
Idx = threadIdx.x + blockIdx.x * blockDim.x
3. 多维线程模型
CUDA可以组织三维的网格和线程块;
blockIdx和threadIdx是类型为uint3的变量,该类型是一个结构体,具有x, y, z三个成员,三个成员都为无符号类型
gridDim和blockDim是类型为dim3的变量,也是一个结构体,具有x,y,z三个成员
取值范围与一维一致
内建变量只在核函数有效,且无需定义
定义多维网格和线程块
dim3 grid_size(Gx, Gy, Gz)
dim3 block_size(Bx, By, Bz)
example:
dim3 grid_size(2, 2) // 等价于dim3 grid_size(2, 2,1)
dim3 block_size(5, 3) // 等价于dim3 block_size(5, 3,1)
多为网格和多维线程块本质是一维的,GPU物理上不分块
每个线程都有唯一标识(二维)
int tid = threadIdx.y * blockDim.x + threadIdx.x;
int bid = blockIdx.y * gridDim.x + blockIdx.x;
图中block(2, 1) bid = 1 * 3 + 2 = 5
thread(3, 2) tid = 2 * 5 + 3
每个线程都有唯一标识(三维)
int tid = threadIdx.z * blockDim.x * blockDim.y (channel) + threadIdx.y * blockDim.x (y dim) + threadIdx.x (x dim);
int bid = blockIdx.z * gridDim.x * gridDim.y + blockIdx.y * gridDim.x + blockIdx.x;
4. 网格和线程块的限制条件
网格大小:
gridDim.x 最大值: \(2^{31} - 1\)
gridDim.y 最大值: \(2^{16} - 1\)
gridDim.z 最大值: \(2^{16} - 1\)
线程块大小限制:
blockDim.x 最大值: 1024
blockDim.y 最大值: 1024
blockDim.z 最大值: 64
注意:线程块总大小最大为1024
三、线程全局索引计算方式
1. 线程全局索引
1.1 一维网格一维线程块
example:
bid = 2;
tid = 1;
id = 8 * 2 + 1 = 17
1.2 二维网格二维线程块

example:
bid = 2 * 1 + 1 = 3;
tid = 4 * 2 + 1 = 9;
id = 4 * 4 * 2 + 9 = 41
1.3 三维网格三维线程块

example:
bid = 0 * 2 * 2 + 1 * 2 + 0 = 2;
tid = 0 * 4 * 4 + 2 * 4 + 1 = 9;
id = 4 * 4 * 2 * bid + tid = 32 * 2 + 9 = 73
2. 不同组合方式列举



四、nvcc编译流程与GPU计算能力
1. nvcc编译流程
1.1 编译流程

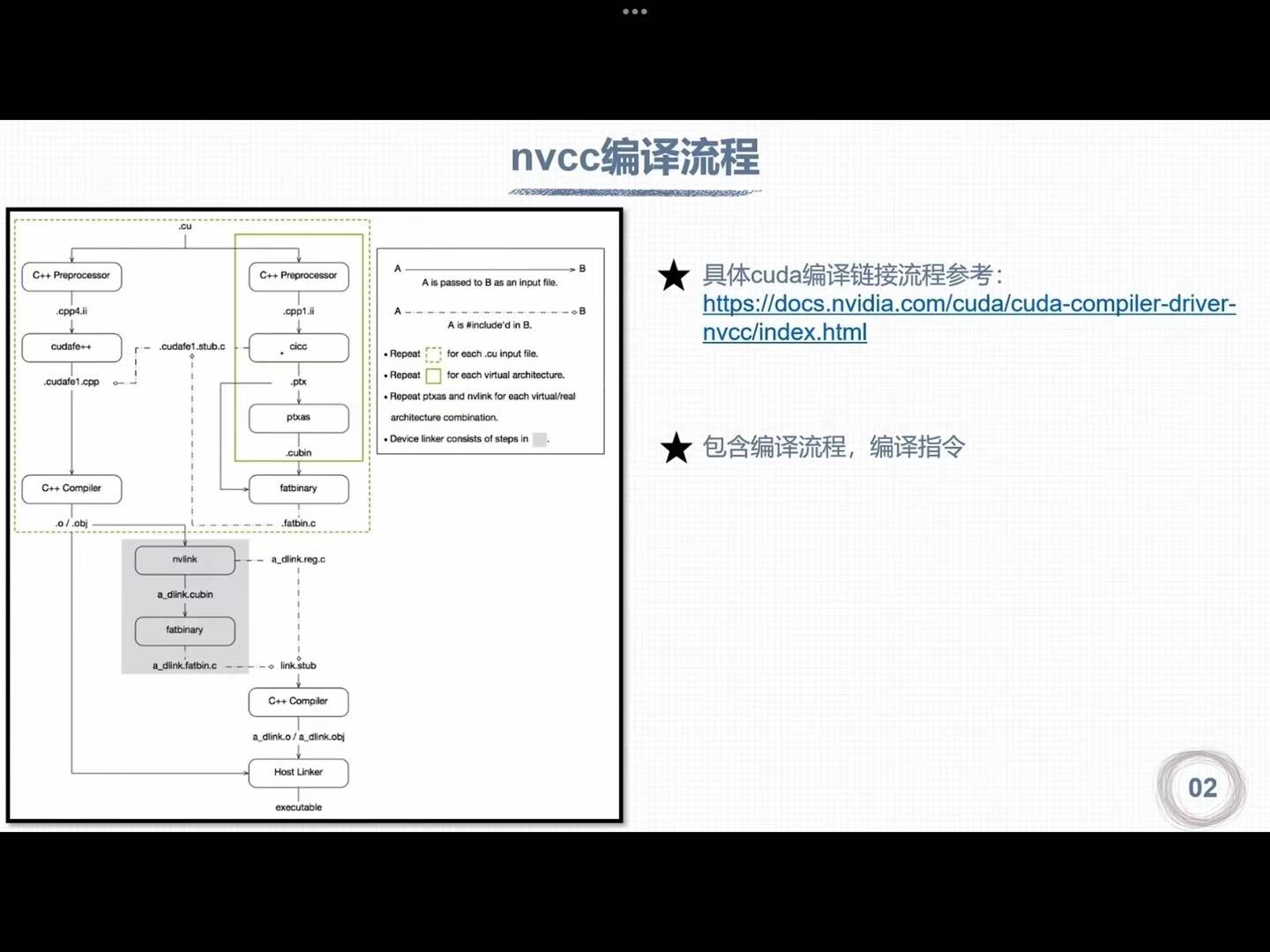
1.2 PTX
PTX作用:虚拟计算架构和真实架构之间的桥梁
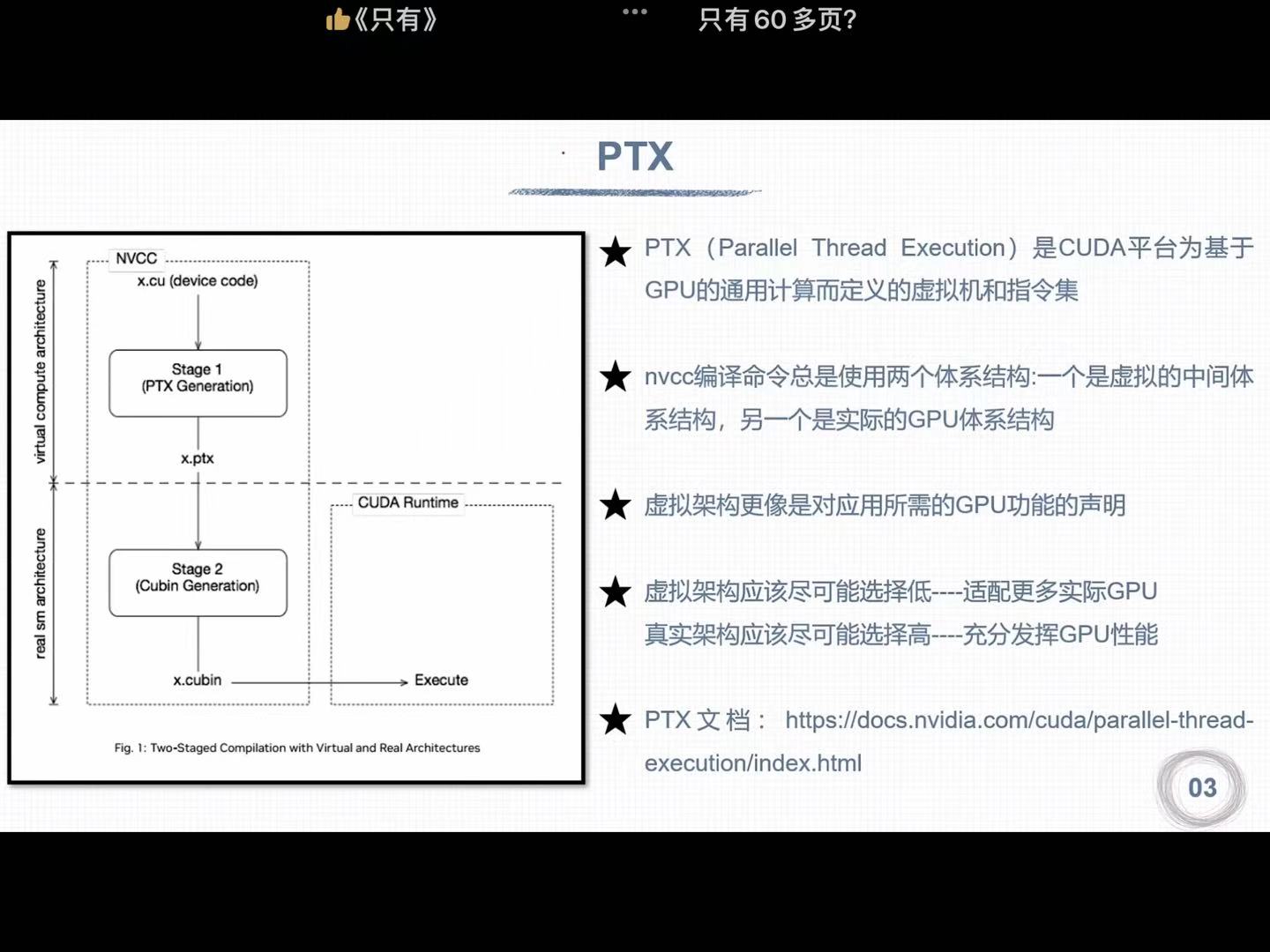
实际计算能力必须高于虚拟计算能力才能编译通过
2. GPU计算能力
不同cubin在不同架构不兼容

主版本号相同的不同架构可以兼容
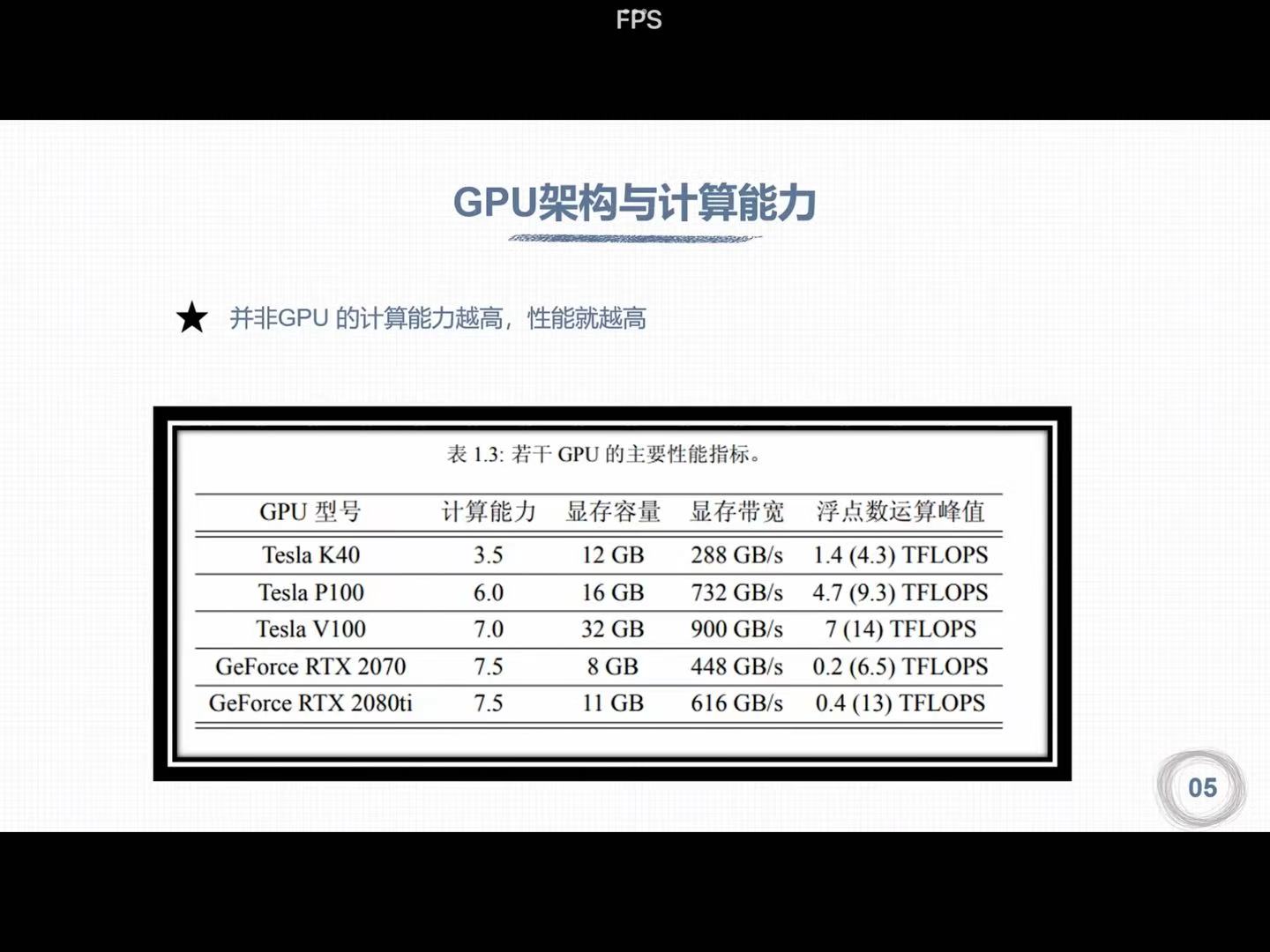
括号中为单精度计算峰值
2070性能低于V100,但是计算能力高于V100
五、CUDA程序兼容性问题
1. 指定虚拟架构计算能力

2. 指定真是架构计算能力

3. 指定多个GPU版本编译

4. nvcc即时编译

缺点:可能不能完全发挥高版本架构的性能
5. nvcc编译默认计算能力

nvcc ***.cu -ptx
通过.target sm_**确认主版本号和次版本号